I am implementing RetinaNet for object detection in this tutorial. RetinaNet is a single stage object detection model that uses Feature Pyramid Networks (FPN) and Focal Loss (FL) to improve its performance in relation to older R-CNN models. RetinaNet works well with dense and small objects.
Object detection is a computer vision and image processing technique that is used to locate instances of objects of a certain class (car, human or cat for example) in images and videos. Object detection involves classification and regression, the model needs to predict the class of objects and the bounding boxes surrounding them.
RetinaNet is a Convolutional Neural Network (CNN) with Feature Pyramid Networks (FPN) and Focal Loss. CNN:s is designed to perform well with images, the arcitecture is inspired by the organization of the visual cortex in the human brain. A CNN reduces images into a form which is easier to process, without sacrificing predictive ability.
A Feature Pyramid Network (FPN) is a feature extractor that generates multiple feature map layers of an image in a pyramidal hierarchical structure. Focal Loss (FL) is an enhancement over Cross-Entropy Loss (CE), it puts more weight to objects that is hard to classify and less weight to objects that is easy to classify. FL focuses on the hard examples.
This code in this tutorial is written in Python and adapted from Keras RetinaNet by Fizyr. I have downloaded a sample of images from Open Images V5 (you can use the latest version) and Keras Functional API is used to build models.
Download Images
You will need to download three .csv files to be able to download a sample of images from the open images project. Browse to Open Images Dataset and download class-descriptions-boxable.csv and train-annotations-bbox.csv, download train-images-boxable.csv from Figure Eight. I choosed to use only three categories (beer, laptop and goat) and 200 images for each class, 80 % is used for training and 20 % for testing/validation.
# Import libraries
import numpy as np
import random
import pandas as pd
from skimage import io
# The main entry point for this module
def main():
# Get classes from file
classes = pd.read_csv('C:\\DATA\\Python-data\\open-images-v5\\class-descriptions-boxable.csv', names=['label', 'name'])
# Get labels for Beer, Laptop and Goat
lbl_beer = classes.loc[classes['name']=='Beer', 'label'].iloc[0]
lbl_laptop = classes.loc[classes['name']=='Laptop', 'label'].iloc[0]
lbl_goat = classes.loc[classes['name']=='Goat', 'label'].iloc[0]
# Print labels
print('Beer: {0}, Laptop: {1}, Goat: {2}'.format(lbl_beer, lbl_laptop, lbl_goat))
# Load dataset of annotations
annotations = pd.read_csv('C:\\DATA\\Python-data\\open-images-v5\\train-annotations-bbox.csv')
# Get objects in annotations file
beer_bbox = annotations[annotations['LabelName']==lbl_beer]
laptop_bbox = annotations[annotations['LabelName']==lbl_laptop]
goat_bbox = annotations[annotations['LabelName']==lbl_goat]
# Print counts
print('There is {0} beer in the dataset.'.format(len(beer_bbox)))
print('There is {0} laptops in the dataset.'.format(len(laptop_bbox)))
print('There is {0} goats in the dataset.'.format(len(goat_bbox)))
# Get images
beer_images = np.unique(beer_bbox['ImageID'])
laptop_images = np.unique(laptop_bbox['ImageID'])
goat_images = np.unique(goat_bbox['ImageID'])
# Print count of images
print('There are {0} images which contain beer'.format(len(beer_images)))
print('There are {0} images which contain laptops'.format(len(laptop_images)))
print('There are {0} images which contain goats'.format(len(goat_images)))
# Variables
n = 200
train_size = int(n*0.8)
base_path = 'C:\\DATA\\Python-data\\open-images-v5\\imgs\\'
# Pick n of each object
beers_subset = beer_images[:n]
laptops_subset = laptop_images[:n]
goats_subset = goat_images[:n]
# Load dataset of images
images = pd.read_csv('C:\\DATA\\Python-data\\open-images-v5\\train-images-boxable.csv')
# Get 3 balanced subsets of images
beer_imgs_subset = [images[images['image_name']==name+'.jpg'] for name in beers_subset]
laptop_imgs_subset = [images[images['image_name']==name+'.jpg'] for name in laptops_subset]
goat_imgs_subset = [images[images['image_name']==name+'.jpg'] for name in goats_subset]
# Download images
for i in range(n):
beer_img = io.imread(beer_imgs_subset[i]['image_url'].values[0])
laptop_img = io.imread(laptop_imgs_subset[i]['image_url'].values[0])
goat_img = io.imread(goat_imgs_subset[i]['image_url'].values[0])
if(i < train_size):
io.imsave(base_path + 'train\\' + beer_imgs_subset[i]['image_name'].values[0], beer_img)
io.imsave(base_path + 'train\\' + laptop_imgs_subset[i]['image_name'].values[0], laptop_img)
io.imsave(base_path + 'train\\' + goat_imgs_subset[i]['image_name'].values[0], goat_img)
else:
io.imsave(base_path + 'test\\' + beer_imgs_subset[i]['image_name'].values[0], beer_img)
io.imsave(base_path + 'test\\' + laptop_imgs_subset[i]['image_name'].values[0], laptop_img)
io.imsave(base_path + 'test\\' + goat_imgs_subset[i]['image_name'].values[0], goat_img)
# Tell python to run main method
if __name__ == "__main__": main()Create Annotations
I have downloaded images and now it is time to create annotation files, one for training and one for testing. Annotation files tells us about the location of objects in images. These files show filename, bounding box and class name for each file and object. One image can include many objects.
# Import libraries
import os
import cv2
import pandas as pd
# Create an annotations file
def create_annotation_file(base_path, annotations, classes, labels, mode='train'):
# Create a dataframe
df = pd.DataFrame(columns=['filename', 'xmin', 'ymin', 'xmax', 'ymax', 'class'])
# Get all images
images = os.listdir(base_path + mode)
# Loop images
for i in range(len(images)):
img_name = images[i]
img_id = img_name.split('.')[0]
tmp_df = annotations[annotations['ImageID']==img_id]
img = cv2.imread((base_path + mode + '\\' + img_name))
height, width = img.shape[:2]
for index, row in tmp_df.iterrows():
label_name = row['LabelName']
for i in range(len(labels)):
if label_name == labels[i]:
df = df.append({
'filename': mode + '\\' + img_name,
'xmin': int(row['XMin'] * width),
'ymin': int(row['YMin'] * height),
'xmax': int(row['XMax'] * width),
'ymax': int(row['YMax'] * height),
'class': classes[i]},
ignore_index=True)
# Save annotations file
df.to_csv(base_path + mode + '_annotations.csv', index=None, header=False)
# The main entry point for this module
def main():
# Variables
base_path = 'C:\\DATA\\Python-data\\open-images-v5\\imgs\\'
classes = ['Beer', 'Laptop', 'Goat']
labels = ['/m/01599', '/m/01c648', '/m/03fwl']
# Load dataset of annotations
annotations = pd.read_csv('C:\\DATA\\Python-data\\open-images-v5\\train-annotations-bbox.csv')
# Create annotation files for train and test
create_annotation_file(base_path, annotations, classes, labels, mode='train')
create_annotation_file(base_path, annotations, classes, labels, mode='test')
# Tell python to run main method
if __name__ == "__main__": main()Classes
I have created a .csv file (classes.csv) with information about the classes that is used in this tutorial. This file is read by the generator.
Laptop,0
Beer,1
Goat,2Common Methods
This module include common methods that is used by many other modules. The methods in this module is used to setup the gpu, to process images and to make transformations.
"""
Copyright 2017-2018 Fizyr (https://fizyr.com)
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
"""
# Import libraries
from __future__ import division
import cv2
import warnings
import keras
import numpy as np
import tensorflow as tf
from PIL import Image
from annytab.retinanet.anchors import AnchorParameters
# The pseudo-random number generator to use.
DEFAULT_PRNG = np.random
# Anchor parameters
anchor_parameters = AnchorParameters(
sizes = [32, 64, 128, 256, 512],
strides = [8, 16, 32, 64, 128],
ratios = np.array([0.125, 0.25, 0.5, 1, 2], keras.backend.floatx()),
scales = np.array([2 ** 0, 2 ** (1.0 / 3.0), 2 ** (2.0 / 3.0)], keras.backend.floatx()))
# Colors
colors = [
[31,0,255],[0,159,255],[255,95,0],[255,19,0],[255,0,0],[255,38,0],[0,255,25],[255,0,133],[255,172,0],[108,0,255],[0,82,255],
[0,255,6],[255,0,152],[223,0,255],[12,0,255],[0,255,178],[108,255,0],[184,0,255],[255,0,76],[146,255,0],[51,0,255],[0,197,255],
[255,248,0],[255,0,19],[255,0,38],[89,255,0],[127,255,0],[255,153,0],[0,255,255],[0,255,216],[0,255,121],[255,0,248],[70,0,255],
[0,255,159],[0,216,255],[0,6,255],[0,63,255],[31,255,0],[255,57,0],[255,0,210],[0,255,102],[242,255,0],[255,191,0],[0,255,63],
[255,0,95],[146,0,255],[184,255,0],[255,114,0],[0,255,235],[255,229,0],[0,178,255],[255,0,114],[255,0,57],[0,140,255],[0,121,255],
[12,255,0],[255,210,0],[0,255,44],[165,255,0],[0,25,255],[0,255,140],[0,101,255],[0,255,82],[223,255,0],[242,0,255],[89,0,255],
[165,0,255],[70,255,0],[255,0,172],[255,76,0],[203,255,0],[204,0,255],[255,0,229],[255,133,0],[127,0,255],[0,235,255],[0,255,197],
[255,0,191],[0,44,255],[50,255,0]
]
# Minimum tensorflow version
MINIMUM_TF_VERSION = 1, 12, 0
# Restrict TensorFlow to only use the one GPU
def setup_gpu(gpu_id):
if tf_version_ok((2, 0, 0)):
if gpu_id == 'cpu' or gpu_id == -1:
tf.config.experimental.set_visible_devices([], 'GPU')
return
# Get all gpus
gpus = tf.config.experimental.list_physical_devices('GPU')
if gpus:
# Restrict TensorFlow to only use the first GPU.
try:
# Currently, memory growth needs to be the same across GPUs.
for gpu in gpus:
tf.config.experimental.set_memory_growth(gpu, True)
# Use only the selcted gpu.
tf.config.experimental.set_visible_devices(gpus[gpu_id], 'GPU')
except RuntimeError as e:
# Visible devices must be set before GPUs have been initialized.
print(e)
logical_gpus = tf.config.experimental.list_logical_devices('GPU')
print(len(gpus), "Physical GPUs,", len(logical_gpus), "Logical GPUs")
else:
import os
if gpu_id == 'cpu' or gpu_id == -1:
os.environ['CUDA_VISIBLE_DEVICES'] = ""
return
os.environ['CUDA_VISIBLE_DEVICES'] = str(gpu_id)
config = tf.ConfigProto()
config.gpu_options.per_process_gpu_memory_fraction = 0.5
config.gpu_options.allow_growth = True
tf.keras.backend.set_session(tf.Session(config=config))
# Get the Tensorflow version
def tf_version():
return tuple(map(int, tf.version.VERSION.split('-')[0].split('.')))
# Check if the current Tensorflow version is higher than the minimum version
def tf_version_ok(minimum_tf_version=MINIMUM_TF_VERSION):
return tf_version() >= minimum_tf_version
# Return a color from a set of predefined colors. Contains 80 colors in total
def label_color(label):
if label < len(colors):
return colors[label]
else:
warnings.warn('Label {} has no color, returning default.'.format(label))
return (0, 255, 0)
# Draws a box on an image with a given color
def draw_box(image, box, color, thickness=2):
b = np.array(box).astype(int)
cv2.rectangle(image, (b[0], b[1]), (b[2], b[3]), color, thickness, cv2.LINE_AA)
# Draws a caption above the box in an image
def draw_caption(image, box, caption):
b = np.array(box).astype(int)
cv2.putText(image, caption, (b[0] + 2, b[1] + 22), cv2.FONT_HERSHEY_DUPLEX, 0.8, (0, 0, 0), 2)
cv2.putText(image, caption, (b[0] + 4, b[1] + 24), cv2.FONT_HERSHEY_DUPLEX, 0.8, (255, 255, 255), 1)
# Draws boxes on an image with a given color
def draw_boxes(image, boxes, color, thickness=2):
for b in boxes:
draw_box(image, b, color, thickness=thickness)
# Draws detections in an image
def draw_detections(image, boxes, scores, labels, color=None, label_to_name=None, score_threshold=0.5):
selection = np.where(scores > score_threshold)[0]
for i in selection:
c = color if color is not None else label_color(labels[i])
draw_box(image, boxes[i, :], color=c)
# draw labels
caption = (label_to_name(labels[i]) if label_to_name else labels[i]) + ': {0:.2f}'.format(scores[i])
draw_caption(image, boxes[i, :], caption)
# Draws annotations in an image
def draw_annotations(image, annotations, color=(0, 255, 0), label_to_name=None):
if isinstance(annotations, np.ndarray):
annotations = {'bboxes': annotations[:, :4], 'labels': annotations[:, 4]}
assert('bboxes' in annotations)
assert('labels' in annotations)
assert(annotations['bboxes'].shape[0] == annotations['labels'].shape[0])
for i in range(annotations['bboxes'].shape[0]):
label = annotations['labels'][i]
c = color if color is not None else label_color(label)
caption = '{}'.format(label_to_name(label) if label_to_name else label)
draw_caption(image, annotations['bboxes'][i], caption)
draw_box(image, annotations['bboxes'][i], color=c)
# Create a numpy array representing a column vector
def colvec(*args):
return np.array([args]).T
# Apply a transformation to an axis aligned bounding box
def transform_aabb(transform, aabb):
x1, y1, x2, y2 = aabb
# Transform all 4 corners of the AABB.
points = transform.dot([
[x1, x2, x1, x2],
[y1, y2, y2, y1],
[1, 1, 1, 1 ],
])
# Extract the min and max corners again.
min_corner = points.min(axis=1)
max_corner = points.max(axis=1)
return [min_corner[0], min_corner[1], max_corner[0], max_corner[1]]
# Construct a random vector between min and max
def _random_vector(min, max, prng=DEFAULT_PRNG):
min = np.array(min)
max = np.array(max)
assert min.shape == max.shape
assert len(min.shape) == 1
return prng.uniform(min, max)
# Construct a homogeneous 2D rotation matrix
def rotation(angle):
return np.array([
[np.cos(angle), -np.sin(angle), 0],
[np.sin(angle), np.cos(angle), 0],
[0, 0, 1]
])
# Construct a random rotation between -max and max
def random_rotation(min, max, prng=DEFAULT_PRNG):
return rotation(prng.uniform(min, max))
# Construct a homogeneous 2D translation matrix
def translation(translation):
return np.array([
[1, 0, translation[0]],
[0, 1, translation[1]],
[0, 0, 1]
])
# Construct a random 2D translation between min and max
def random_translation(min, max, prng=DEFAULT_PRNG):
return translation(_random_vector(min, max, prng))
# Construct a homogeneous 2D shear matrix
def shear(angle):
return np.array([
[1, -np.sin(angle), 0],
[0, np.cos(angle), 0],
[0, 0, 1]
])
# Construct a random 2D shear matrix with shear angle between -max and max
def random_shear(min, max, prng=DEFAULT_PRNG):
return shear(prng.uniform(min, max))
# Construct a homogeneous 2D scaling matrix
def scaling(factor):
return np.array([
[factor[0], 0, 0],
[0, factor[1], 0],
[0, 0, 1]
])
# Construct a random 2D scale matrix between -max and max
def random_scaling(min, max, prng=DEFAULT_PRNG):
return scaling(_random_vector(min, max, prng))
# Construct a transformation randomly containing X/Y flips (or not)
def random_flip(flip_x_chance, flip_y_chance, prng=DEFAULT_PRNG):
flip_x = prng.uniform(0, 1) < flip_x_chance
flip_y = prng.uniform(0, 1) < flip_y_chance
# 1 - 2 * bool gives 1 for False and -1 for True.
return scaling((1 - 2 * flip_x, 1 - 2 * flip_y))
# Create a new transform representing the same transformation, only with the origin of the linear part changed
def change_transform_origin(transform, center):
center = np.array(center)
return np.linalg.multi_dot([translation(center), transform, translation(-center)])
# Create a random transformation.
def random_transform(
min_rotation=0,
max_rotation=0,
min_translation=(0, 0),
max_translation=(0, 0),
min_shear=0,
max_shear=0,
min_scaling=(1, 1),
max_scaling=(1, 1),
flip_x_chance=0,
flip_y_chance=0,
prng=DEFAULT_PRNG
):
return np.linalg.multi_dot([
random_rotation(min_rotation, max_rotation, prng),
random_translation(min_translation, max_translation, prng),
random_shear(min_shear, max_shear, prng),
random_scaling(min_scaling, max_scaling, prng),
random_flip(flip_x_chance, flip_y_chance, prng)
])
# Create a random transform generator
def random_transform_generator(prng=None, **kwargs):
if prng is None:
# RandomState automatically seeds using the best available method
prng = np.random.RandomState()
while True:
yield random_transform(prng=prng, **kwargs)
# Applies deltas (usually regression results) to boxes (usually anchors)
def bbox_transform_inv(boxes, deltas, mean=None, std=None):
if mean is None:
mean = [0, 0, 0, 0]
if std is None:
std = [0.2, 0.2, 0.2, 0.2]
width = boxes[:, :, 2] - boxes[:, :, 0]
height = boxes[:, :, 3] - boxes[:, :, 1]
x1 = boxes[:, :, 0] + (deltas[:, :, 0] * std[0] + mean[0]) * width
y1 = boxes[:, :, 1] + (deltas[:, :, 1] * std[1] + mean[1]) * height
x2 = boxes[:, :, 2] + (deltas[:, :, 2] * std[2] + mean[2]) * width
y2 = boxes[:, :, 3] + (deltas[:, :, 3] * std[3] + mean[3]) * height
pred_boxes = keras.backend.stack([x1, y1, x2, y2], axis=2)
return pred_boxes
# Read an image in BGR format
def read_image_bgr(path):
# We deliberately don't use cv2.imread here, since it gives no feedback on errors while reading the image.
image = np.asarray(Image.open(path).convert('RGB'))
return image[:, :, ::-1].copy()
# Preprocess an image by subtracting the ImageNet mean
def preprocess_image(x, mode='caffe'):
# covert always to float32 to keep compatibility with opencv
x = x.astype(np.float32)
if mode == 'tf':
x /= 127.5
x -= 1.
elif mode == 'caffe':
x[..., 0] -= 103.939
x[..., 1] -= 116.779
x[..., 2] -= 123.68
return x
# Adjust a transformation for a specific image
def adjust_transform_for_image(transform, image, relative_translation):
height, width, channels = image.shape
result = transform
# Scale the translation with the image size if specified.
if relative_translation:
result[0:2, 2] *= [width, height]
# Move the origin of transformation.
result = change_transform_origin(transform, (0.5 * width, 0.5 * height))
return result
# Struct holding parameters determining how to apply a transformation to an image
class TransformParameters:
def __init__(
self,
fill_mode = 'nearest',
interpolation = 'linear',
cval = 0,
relative_translation = True,
):
self.fill_mode = fill_mode
self.cval = cval
self.interpolation = interpolation
self.relative_translation = relative_translation
def cvBorderMode(self):
if self.fill_mode == 'constant':
return cv2.BORDER_CONSTANT
if self.fill_mode == 'nearest':
return cv2.BORDER_REPLICATE
if self.fill_mode == 'reflect':
return cv2.BORDER_REFLECT_101
if self.fill_mode == 'wrap':
return cv2.BORDER_WRAP
def cvInterpolation(self):
if self.interpolation == 'nearest':
return cv2.INTER_NEAREST
if self.interpolation == 'linear':
return cv2.INTER_LINEAR
if self.interpolation == 'cubic':
return cv2.INTER_CUBIC
if self.interpolation == 'area':
return cv2.INTER_AREA
if self.interpolation == 'lanczos4':
return cv2.INTER_LANCZOS4
# Apply a transformation to an image
def apply_transform(matrix, image, params):
output = cv2.warpAffine(
image,
matrix[:2, :],
dsize = (image.shape[1], image.shape[0]),
flags = params.cvInterpolation(),
borderMode = params.cvBorderMode(),
borderValue = params.cval,
)
return output
# Compute an image scale such that the image size is constrained to min_side and max_side
def compute_resize_scale(image_shape, min_side=800, max_side=1333):
(rows, cols, _) = image_shape
smallest_side = min(rows, cols)
# rescale the image so the smallest side is min_side
scale = min_side / smallest_side
# check if the largest side is now greater than max_side, which can happen
# when images have a large aspect ratio
largest_side = max(rows, cols)
if largest_side * scale > max_side:
scale = max_side / largest_side
return scale
# Resize an image such that the size is constrained to min_side and max_side
def resize_image(img, min_side=800, max_side=1333):
# compute scale to resize the image
scale = compute_resize_scale(img.shape, min_side=min_side, max_side=max_side)
# resize the image with the computed scale
img = cv2.resize(img, None, fx=scale, fy=scale)
return img, scale
# Uniformly sample from the given range
def _uniform(val_range):
return np.random.uniform(val_range[0], val_range[1])
# Check whether the range is a valid range
def _check_range(val_range, min_val=None, max_val=None):
if val_range[0] > val_range[1]:
raise ValueError('interval lower bound > upper bound')
if min_val is not None and val_range[0] < min_val:
raise ValueError('invalid interval lower bound')
if max_val is not None and val_range[1] > max_val:
raise ValueError('invalid interval upper bound')
# Clip and convert an image to np.uint8
def _clip(image):
return np.clip(image, 0, 255).astype(np.uint8)
# Struct holding parameters and applying image color transformation
class VisualEffect:
def __init__(
self,
contrast_factor,
brightness_delta,
hue_delta,
saturation_factor,
):
self.contrast_factor = contrast_factor
self.brightness_delta = brightness_delta
self.hue_delta = hue_delta
self.saturation_factor = saturation_factor
# Apply a visual effect on the image
def __call__(self, image):
if self.contrast_factor:
image = adjust_contrast(image, self.contrast_factor)
if self.brightness_delta:
image = adjust_brightness(image, self.brightness_delta)
if self.hue_delta or self.saturation_factor:
image = cv2.cvtColor(image, cv2.COLOR_BGR2HSV)
if self.hue_delta:
image = adjust_hue(image, self.hue_delta)
if self.saturation_factor:
image = adjust_saturation(image, self.saturation_factor)
image = cv2.cvtColor(image, cv2.COLOR_HSV2BGR)
return image
# Generate visual effect parameters uniformly sampled from the given intervals
def random_visual_effect_generator(
contrast_range=(0.9, 1.1),
brightness_range=(-.1, .1),
hue_range=(-0.05, 0.05),
saturation_range=(0.95, 1.05)
):
_check_range(contrast_range, 0)
_check_range(brightness_range, -1, 1)
_check_range(hue_range, -1, 1)
_check_range(saturation_range, 0)
def _generate():
while True:
yield VisualEffect(
contrast_factor=_uniform(contrast_range),
brightness_delta=_uniform(brightness_range),
hue_delta=_uniform(hue_range),
saturation_factor=_uniform(saturation_range),
)
return _generate()
# Adjust contrast of an image
def adjust_contrast(image, factor):
mean = image.mean(axis=0).mean(axis=0)
return _clip((image - mean) * factor + mean)
# Adjust brightness of an image
def adjust_brightness(image, delta):
return _clip(image + delta * 255)
# Adjust hue of an image
def adjust_hue(image, delta):
image[..., 0] = np.mod(image[..., 0] + delta * 180, 180)
return image
# Adjust saturation of an image
def adjust_saturation(image, factor):
image[..., 1] = np.clip(image[..., 1] * factor, 0 , 255)
return imageGenerator
This is an abstract base class for a generator, specialized generators can inherit properties and methods from this base generator. A generator is used to generate input data for training and evaluation.
"""
Copyright 2017-2018 Fizyr (https://fizyr.com)
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
"""
# Import libraries
import numpy as np
import random
import warnings
import keras
from annytab.retinanet.anchors import (
anchor_targets_bbox,
anchors_for_shape,
guess_shapes
)
from annytab.retinanet.common import (
TransformParameters,
adjust_transform_for_image,
apply_transform,
preprocess_image,
resize_image,
)
from annytab.retinanet.common import transform_aabb
import annytab.retinanet.common as common
# Abstract generator class
class Generator(keras.utils.Sequence):
def __init__(
self,
transform_generator = None,
visual_effect_generator=None,
batch_size=1,
group_method='ratio', # one of 'none', 'random', 'ratio'
shuffle_groups=True,
image_min_side=800,
image_max_side=1333,
no_resize=False,
transform_parameters=None,
compute_anchor_targets=anchor_targets_bbox,
compute_shapes=guess_shapes,
preprocess_image=preprocess_image,
config=None
):
self.transform_generator = transform_generator
self.visual_effect_generator = visual_effect_generator
self.batch_size = int(batch_size)
self.group_method = group_method
self.shuffle_groups = shuffle_groups
self.image_min_side = image_min_side
self.image_max_side = image_max_side
self.no_resize = no_resize
self.transform_parameters = transform_parameters or TransformParameters()
self.compute_anchor_targets = compute_anchor_targets
self.compute_shapes = compute_shapes
self.preprocess_image = preprocess_image
self.config = config
# Define groups
self.group_images()
# Shuffle when initializing
if self.shuffle_groups:
self.on_epoch_end()
def on_epoch_end(self):
if self.shuffle_groups:
random.shuffle(self.groups)
# Size of the dataset
def size(self):
raise NotImplementedError('size method not implemented')
# Number of classes in the dataset
def num_classes(self):
raise NotImplementedError('num_classes method not implemented')
# Returns True if label is a known label
def has_label(self, label):
raise NotImplementedError('has_label method not implemented')
# Returns True if name is a known class
def has_name(self, name):
raise NotImplementedError('has_name method not implemented')
# Map name to label
def name_to_label(self, name):
raise NotImplementedError('name_to_label method not implemented')
# Map label to name
def label_to_name(self, label):
raise NotImplementedError('label_to_name method not implemented')
# Compute the aspect ratio for an image with image_index
def image_aspect_ratio(self, image_index):
raise NotImplementedError('image_aspect_ratio method not implemented')
# Load an image at the image_index
def load_image(self, image_index):
raise NotImplementedError('load_image method not implemented')
# Load annotations for an image_index
def load_annotations(self, image_index):
raise NotImplementedError('load_annotations method not implemented')
# Load annotations for all images in group
def load_annotations_group(self, group):
annotations_group = [self.load_annotations(image_index) for image_index in group]
for annotations in annotations_group:
assert(isinstance(annotations, dict)), '\'load_annotations\' should return a list of dictionaries, received: {}'.format(type(annotations))
assert('labels' in annotations), '\'load_annotations\' should return a list of dictionaries that contain \'labels\' and \'bboxes\'.'
assert('bboxes' in annotations), '\'load_annotations\' should return a list of dictionaries that contain \'labels\' and \'bboxes\'.'
return annotations_group
# Filter annotations by removing those that are outside of the image bounds or whose width/height < 0
def filter_annotations(self, image_group, annotations_group, group):
# test all annotations
for index, (image, annotations) in enumerate(zip(image_group, annotations_group)):
# test x2 < x1 | y2 < y1 | x1 < 0 | y1 < 0 | x2 <= 0 | y2 <= 0 | x2 >= image.shape[1] | y2 >= image.shape[0]
invalid_indices = np.where(
(annotations['bboxes'][:, 2] <= annotations['bboxes'][:, 0]) |
(annotations['bboxes'][:, 3] <= annotations['bboxes'][:, 1]) |
(annotations['bboxes'][:, 0] < 0) |
(annotations['bboxes'][:, 1] < 0) |
(annotations['bboxes'][:, 2] > image.shape[1]) |
(annotations['bboxes'][:, 3] > image.shape[0])
)[0]
# delete invalid indices
if len(invalid_indices):
warnings.warn('Image with id {} (shape {}) contains the following invalid boxes: {}.'.format(
group[index],
image.shape,
annotations['bboxes'][invalid_indices, :]
))
for k in annotations_group[index].keys():
annotations_group[index][k] = np.delete(annotations[k], invalid_indices, axis=0)
return image_group, annotations_group
# Load images for all images in a group
def load_image_group(self, group):
return [self.load_image(image_index) for image_index in group]
# Randomly transforms image and annotation
def random_visual_effect_group_entry(self, image, annotations):
visual_effect = next(self.visual_effect_generator)
# apply visual effect
image = visual_effect(image)
return image, annotations
# Randomly apply visual effect on each image
def random_visual_effect_group(self, image_group, annotations_group):
assert(len(image_group) == len(annotations_group))
if self.visual_effect_generator is None:
# do nothing
return image_group, annotations_group
for index in range(len(image_group)):
# apply effect on a single group entry
image_group[index], annotations_group[index] = self.random_visual_effect_group_entry(
image_group[index], annotations_group[index]
)
return image_group, annotations_group
# Randomly transforms image and annotation
def random_transform_group_entry(self, image, annotations, transform=None):
# randomly transform both image and annotations
if transform is not None or self.transform_generator:
if transform is None:
transform = adjust_transform_for_image(next(self.transform_generator), image, self.transform_parameters.relative_translation)
# apply transformation to image
image = apply_transform(transform, image, self.transform_parameters)
# Transform the bounding boxes in the annotations.
annotations['bboxes'] = annotations['bboxes'].copy()
for index in range(annotations['bboxes'].shape[0]):
annotations['bboxes'][index, :] = transform_aabb(transform, annotations['bboxes'][index, :])
return image, annotations
# Randomly transforms each image and its annotations
def random_transform_group(self, image_group, annotations_group):
assert(len(image_group) == len(annotations_group))
for index in range(len(image_group)):
# transform a single group entry
image_group[index], annotations_group[index] = self.random_transform_group_entry(image_group[index], annotations_group[index])
return image_group, annotations_group
# Resize an image using image_min_side and image_max_side
def resize_image(self, image):
if self.no_resize:
return image, 1
else:
return resize_image(image, min_side=self.image_min_side, max_side=self.image_max_side)
# Preprocess image and its annotations
def preprocess_group_entry(self, image, annotations):
# preprocess the image
image = self.preprocess_image(image)
# resize image
image, image_scale = self.resize_image(image)
# apply resizing to annotations too
annotations['bboxes'] *= image_scale
# convert to the wanted keras floatx
image = keras.backend.cast_to_floatx(image)
return image, annotations
# Preprocess each image and its annotations in its group
def preprocess_group(self, image_group, annotations_group):
assert(len(image_group) == len(annotations_group))
for index in range(len(image_group)):
# preprocess a single group entry
image_group[index], annotations_group[index] = self.preprocess_group_entry(image_group[index], annotations_group[index])
return image_group, annotations_group
# Order the images according to self.order and makes groups of self.batch_size
def group_images(self):
# determine the order of the images
order = list(range(self.size()))
if self.group_method == 'random':
random.shuffle(order)
elif self.group_method == 'ratio':
order.sort(key=lambda x: self.image_aspect_ratio(x))
# divide into groups, one group = one batch
self.groups = [[order[x % len(order)] for x in range(i, i + self.batch_size)] for i in range(0, len(order), self.batch_size)]
# Compute inputs for the network using an image_group
def compute_inputs(self, image_group):
# get the max image shape
max_shape = tuple(max(image.shape[x] for image in image_group) for x in range(3))
# construct an image batch object
image_batch = np.zeros((self.batch_size,) + max_shape, dtype=keras.backend.floatx())
# copy all images to the upper left part of the image batch object
for image_index, image in enumerate(image_group):
image_batch[image_index, :image.shape[0], :image.shape[1], :image.shape[2]] = image
if keras.backend.image_data_format() == 'channels_first':
image_batch = image_batch.transpose((0, 3, 1, 2))
return image_batch
# Generate anchors
def generate_anchors(self, image_shape):
anchor_params = common.anchor_parameters
if self.config and 'anchor_parameters' in self.config:
anchor_params = parse_anchor_parameters(self.config)
return anchors_for_shape(image_shape, anchor_params=anchor_params, shapes_callback=self.compute_shapes)
# Compute target outputs for the network using images and their annotations
def compute_targets(self, image_group, annotations_group):
# get the max image shape
max_shape = tuple(max(image.shape[x] for image in image_group) for x in range(3))
anchors = self.generate_anchors(max_shape)
batches = self.compute_anchor_targets(
anchors,
image_group,
annotations_group,
self.num_classes()
)
return list(batches)
# Compute inputs and target outputs for the network
def compute_input_output(self, group):
# load images and annotations
image_group = self.load_image_group(group)
annotations_group = self.load_annotations_group(group)
# check validity of annotations
image_group, annotations_group = self.filter_annotations(image_group, annotations_group, group)
# randomly apply visual effect
image_group, annotations_group = self.random_visual_effect_group(image_group, annotations_group)
# randomly transform data
image_group, annotations_group = self.random_transform_group(image_group, annotations_group)
# perform preprocessing steps
image_group, annotations_group = self.preprocess_group(image_group, annotations_group)
# compute network inputs
inputs = self.compute_inputs(image_group)
# compute network targets
targets = self.compute_targets(image_group, annotations_group)
return inputs, targets
# Number of batches for generator
def __len__(self):
return len(self.groups)
# Keras sequence method for generating batches
def __getitem__(self, index):
group = self.groups[index]
inputs, targets = self.compute_input_output(group)
return inputs, targetsCSV Generator
This is a specialized generator that generates data from .csv files. The Pascal VOC format is more efficient if the dataset is large, .csv data works well for the dataset in this tutorial.
"""
Copyright 2017-2018 yhenon (https://github.com/yhenon/)
Copyright 2017-2018 Fizyr (https://fizyr.com)
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
"""
# Import libraries
import numpy as np
from PIL import Image
from six import raise_from
import csv
import sys
import os.path
from collections import OrderedDict
from annytab.retinanet.generator import Generator
from annytab.retinanet.common import read_image_bgr
# Parse a string into a value, and format a nice ValueError if it fails
def _parse(value, function, fmt):
try:
return function(value)
except ValueError as e:
raise_from(ValueError(fmt.format(e)), None)
# Parse the classes file given by csv_reader
def _read_classes(csv_reader):
result = OrderedDict()
for line, row in enumerate(csv_reader):
line += 1
try:
class_name, class_id = row
except ValueError:
raise_from(ValueError('line {}: format should be \'class_name, class_id\''.format(line)), None)
class_id = _parse(class_id, int, 'line {}: malformed class ID: {{}}'.format(line))
if class_name in result:
raise ValueError('line {}: duplicate class name: \'{}\''.format(line, class_name))
result[class_name] = class_id
return result
# Read annotations from the csv_reader
def _read_annotations(csv_reader, classes):
result = OrderedDict()
for line, row in enumerate(csv_reader):
line += 1
try:
img_file, x1, y1, x2, y2, class_name = row[:6]
except ValueError:
raise_from(ValueError('line {}: format should be \'img_file,x1,y1,x2,y2,class_name\' or \'img_file,,,,,\''.format(line)), None)
if img_file not in result:
result[img_file] = []
# If a row contains only an image path, it's an image without annotations.
if (x1, y1, x2, y2, class_name) == ('', '', '', '', ''):
continue
x1 = _parse(x1, int, 'line {}: malformed x1: {{}}'.format(line))
y1 = _parse(y1, int, 'line {}: malformed y1: {{}}'.format(line))
x2 = _parse(x2, int, 'line {}: malformed x2: {{}}'.format(line))
y2 = _parse(y2, int, 'line {}: malformed y2: {{}}'.format(line))
# Check that the bounding box is valid.
if x2 <= x1:
raise ValueError('line {}: x2 ({}) must be higher than x1 ({})'.format(line, x2, x1))
if y2 <= y1:
raise ValueError('line {}: y2 ({}) must be higher than y1 ({})'.format(line, y2, y1))
# check if the current class name is correctly present
if class_name not in classes:
raise ValueError('line {}: unknown class name: \'{}\' (classes: {})'.format(line, class_name, classes))
result[img_file].append({'x1': x1, 'x2': x2, 'y1': y1, 'y2': y2, 'class': class_name})
return result
# Open a file with flags suitable for csv.reader
def _open_for_csv(path):
if sys.version_info[0] < 3:
return open(path, 'rb')
else:
return open(path, 'r', newline='')
# Generate data for a custom CSV dataset
class CSVGenerator(Generator):
def __init__(
self,
csv_data_file,
csv_class_file,
base_dir=None,
**kwargs
):
self.image_names = []
self.image_data = {}
self.base_dir = base_dir
# Take base_dir from annotations file if not explicitly specified.
if self.base_dir is None:
self.base_dir = os.path.dirname(csv_data_file)
# parse the provided class file
try:
with _open_for_csv(csv_class_file) as file:
self.classes = _read_classes(csv.reader(file, delimiter=','))
except ValueError as e:
raise_from(ValueError('invalid CSV class file: {}: {}'.format(csv_class_file, e)), None)
self.labels = {}
for key, value in self.classes.items():
self.labels[value] = key
# csv with img_path, x1, y1, x2, y2, class_name
try:
with _open_for_csv(csv_data_file) as file:
self.image_data = _read_annotations(csv.reader(file, delimiter=','), self.classes)
except ValueError as e:
raise_from(ValueError('invalid CSV annotations file: {}: {}'.format(csv_data_file, e)), None)
self.image_names = list(self.image_data.keys())
super(CSVGenerator, self).__init__(**kwargs)
# Size of the dataset
def size(self):
return len(self.image_names)
# Number of classes in the dataset
def num_classes(self):
return max(self.classes.values()) + 1
# Return True if label is a known label
def has_label(self, label):
return label in self.labels
# Returns True if name is a known class
def has_name(self, name):
return name in self.classes
# Map name to label
def name_to_label(self, name):
return self.classes[name]
# Map label to name
def label_to_name(self, label):
return self.labels[label]
# Returns the image path for image_index
def image_path(self, image_index):
return os.path.join(self.base_dir, self.image_names[image_index])
# Compute the aspect ratio for an image with image_index
def image_aspect_ratio(self, image_index):
# PIL is fast for metadata
image = Image.open(self.image_path(image_index))
return float(image.width) / float(image.height)
# Load an image at the image_index
def load_image(self, image_index):
return read_image_bgr(self.image_path(image_index))
# Load annotations for an image_index
def load_annotations(self, image_index):
path = self.image_names[image_index]
annotations = {'labels': np.empty((0,)), 'bboxes': np.empty((0, 4))}
for idx, annot in enumerate(self.image_data[path]):
annotations['labels'] = np.concatenate((annotations['labels'], [self.name_to_label(annot['class'])]))
annotations['bboxes'] = np.concatenate((annotations['bboxes'], [[
float(annot['x1']),
float(annot['y1']),
float(annot['x2']),
float(annot['y2']),
]]))
return annotationsAnchors
This module is used to generate anchors for objects. Multiple anchor boxes is generated for objects in order to find the bounding box with the best fit.
"""
Copyright 2017-2018 Fizyr (https://fizyr.com)
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
"""
# Import libraries
import numpy as np
import keras
# The parameters that define how anchors are generated
class AnchorParameters:
# Initialize the class
def __init__(self, sizes, strides, ratios, scales):
self.sizes = sizes
self.strides = strides
self.ratios = ratios
self.scales = scales
# Get the number of anchors
def num_anchors(self):
return len(self.ratios) * len(self.scales)
# Default anchor parameters
AnchorParameters.default = AnchorParameters(
sizes = [32, 64, 128, 256, 512],
strides = [8, 16, 32, 64, 128],
ratios = np.array([0.5, 1, 2], keras.backend.floatx()),
scales = np.array([2 ** 0, 2 ** (1.0 / 3.0), 2 ** (2.0 / 3.0)], keras.backend.floatx()),
)
# Compute overlap
def compute_overlap(boxes, query_boxes):
N = boxes.shape[0]
K = query_boxes.shape[0]
overlaps = np.zeros((N, K), dtype=np.float64)
iw = 0.0
ih = 0.0
box_area = 0.0
ua = 0.0
k = 0.0
n = 0.0
for k in range(K):
box_area = (
(query_boxes[k, 2] - query_boxes[k, 0] + 1) *
(query_boxes[k, 3] - query_boxes[k, 1] + 1)
)
for n in range(N):
iw = (
min(boxes[n, 2], query_boxes[k, 2]) -
max(boxes[n, 0], query_boxes[k, 0]) + 1
)
if iw > 0:
ih = (
min(boxes[n, 3], query_boxes[k, 3]) -
max(boxes[n, 1], query_boxes[k, 1]) + 1
)
if ih > 0:
ua = np.float64(
(boxes[n, 2] - boxes[n, 0] + 1) *
(boxes[n, 3] - boxes[n, 1] + 1) +
box_area - iw * ih
)
overlaps[n, k] = iw * ih / ua
return overlaps
# Generate anchor targets for bbox detection
def anchor_targets_bbox(
anchors,
image_group,
annotations_group,
num_classes,
negative_overlap=0.4,
positive_overlap=0.5
):
assert(len(image_group) == len(annotations_group)), "The length of the images and annotations need to be equal."
assert(len(annotations_group) > 0), "No data received to compute anchor targets for."
for annotations in annotations_group:
assert('bboxes' in annotations), "Annotations should contain bboxes."
assert('labels' in annotations), "Annotations should contain labels."
batch_size = len(image_group)
regression_batch = np.zeros((batch_size, anchors.shape[0], 4 + 1), dtype=keras.backend.floatx())
labels_batch = np.zeros((batch_size, anchors.shape[0], num_classes + 1), dtype=keras.backend.floatx())
# compute labels and regression targets
for index, (image, annotations) in enumerate(zip(image_group, annotations_group)):
if annotations['bboxes'].shape[0]:
# obtain indices of gt annotations with the greatest overlap
positive_indices, ignore_indices, argmax_overlaps_inds = compute_gt_annotations(anchors, annotations['bboxes'], negative_overlap, positive_overlap)
labels_batch[index, ignore_indices, -1] = -1
labels_batch[index, positive_indices, -1] = 1
regression_batch[index, ignore_indices, -1] = -1
regression_batch[index, positive_indices, -1] = 1
# compute target class labels
labels_batch[index, positive_indices, annotations['labels'][argmax_overlaps_inds[positive_indices]].astype(int)] = 1
regression_batch[index, :, :-1] = bbox_transform(anchors, annotations['bboxes'][argmax_overlaps_inds, :])
# ignore annotations outside of image
if image.shape:
anchors_centers = np.vstack([(anchors[:, 0] + anchors[:, 2]) / 2, (anchors[:, 1] + anchors[:, 3]) / 2]).T
indices = np.logical_or(anchors_centers[:, 0] >= image.shape[1], anchors_centers[:, 1] >= image.shape[0])
labels_batch[index, indices, -1] = -1
regression_batch[index, indices, -1] = -1
return regression_batch, labels_batch
# Obtain indices of gt annotations with the greatest overlap
def compute_gt_annotations(
anchors,
annotations,
negative_overlap=0.4,
positive_overlap=0.5
):
overlaps = compute_overlap(anchors.astype(np.float64), annotations.astype(np.float64))
argmax_overlaps_inds = np.argmax(overlaps, axis=1)
max_overlaps = overlaps[np.arange(overlaps.shape[0]), argmax_overlaps_inds]
# assign "dont care" labels
positive_indices = max_overlaps >= positive_overlap
ignore_indices = (max_overlaps > negative_overlap) & ~positive_indices
return positive_indices, ignore_indices, argmax_overlaps_inds
# Compute layer shapes given input image shape and the model
def layer_shapes(image_shape, model):
shape = {
model.layers[0].name: (None,) + image_shape,
}
for layer in model.layers[1:]:
nodes = layer._inbound_nodes
for node in nodes:
inputs = [shape[lr.name] for lr in node.inbound_layers]
if not inputs:
continue
shape[layer.name] = layer.compute_output_shape(inputs[0] if len(inputs) == 1 else inputs)
return shape
# Make a function for getting the shape of the pyramid levels
def make_shapes_callback(model):
def get_shapes(image_shape, pyramid_levels):
shape = layer_shapes(image_shape, model)
image_shapes = [shape["P{}".format(level)][1:3] for level in pyramid_levels]
return image_shapes
return get_shapes
# Guess shapes based on pyramid levels
def guess_shapes(image_shape, pyramid_levels):
image_shape = np.array(image_shape[:2])
image_shapes = [(image_shape + 2 ** x - 1) // (2 ** x) for x in pyramid_levels]
return image_shapes
# Generators anchors for a given shape
def anchors_for_shape(
image_shape,
pyramid_levels=None,
anchor_params=None,
shapes_callback=None,
):
if pyramid_levels is None:
pyramid_levels = [3, 4, 5, 6, 7]
if anchor_params is None:
anchor_params = AnchorParameters.default
if shapes_callback is None:
shapes_callback = guess_shapes
image_shapes = shapes_callback(image_shape, pyramid_levels)
# compute anchors over all pyramid levels
all_anchors = np.zeros((0, 4))
for idx, p in enumerate(pyramid_levels):
anchors = generate_anchors(
base_size=anchor_params.sizes[idx],
ratios=anchor_params.ratios,
scales=anchor_params.scales
)
shifted_anchors = shift(image_shapes[idx], anchor_params.strides[idx], anchors)
all_anchors = np.append(all_anchors, shifted_anchors, axis=0)
return all_anchors
# Produce shifted anchors based on shape of the map and stride size
def shift(shape, stride, anchors):
# create a grid starting from half stride from the top left corner
shift_x = (np.arange(0, shape[1]) + 0.5) * stride
shift_y = (np.arange(0, shape[0]) + 0.5) * stride
shift_x, shift_y = np.meshgrid(shift_x, shift_y)
shifts = np.vstack((
shift_x.ravel(), shift_y.ravel(),
shift_x.ravel(), shift_y.ravel()
)).transpose()
# add A anchors (1, A, 4) to
# cell K shifts (K, 1, 4) to get
# shift anchors (K, A, 4)
# reshape to (K*A, 4) shifted anchors
A = anchors.shape[0]
K = shifts.shape[0]
all_anchors = (anchors.reshape((1, A, 4)) + shifts.reshape((1, K, 4)).transpose((1, 0, 2)))
all_anchors = all_anchors.reshape((K * A, 4))
return all_anchors
# Generate anchor (reference) windows by enumerating aspect ratios X scales w.r.t. a reference window
def generate_anchors(base_size=16, ratios=None, scales=None):
if ratios is None:
ratios = AnchorParameters.default.ratios
if scales is None:
scales = AnchorParameters.default.scales
num_anchors = len(ratios) * len(scales)
# initialize output anchors
anchors = np.zeros((num_anchors, 4))
# scale base_size
anchors[:, 2:] = base_size * np.tile(scales, (2, len(ratios))).T
# compute areas of anchors
areas = anchors[:, 2] * anchors[:, 3]
# correct for ratios
anchors[:, 2] = np.sqrt(areas / np.repeat(ratios, len(scales)))
anchors[:, 3] = anchors[:, 2] * np.repeat(ratios, len(scales))
# transform from (x_ctr, y_ctr, w, h) -> (x1, y1, x2, y2)
anchors[:, 0::2] -= np.tile(anchors[:, 2] * 0.5, (2, 1)).T
anchors[:, 1::2] -= np.tile(anchors[:, 3] * 0.5, (2, 1)).T
return anchors
# Compute bounding-box regression targets for an image
def bbox_transform(anchors, gt_boxes, mean=None, std=None):
if mean is None:
mean = np.array([0, 0, 0, 0])
if std is None:
std = np.array([0.2, 0.2, 0.2, 0.2])
if isinstance(mean, (list, tuple)):
mean = np.array(mean)
elif not isinstance(mean, np.ndarray):
raise ValueError('Expected mean to be a np.ndarray, list or tuple. Received: {}'.format(type(mean)))
if isinstance(std, (list, tuple)):
std = np.array(std)
elif not isinstance(std, np.ndarray):
raise ValueError('Expected std to be a np.ndarray, list or tuple. Received: {}'.format(type(std)))
anchor_widths = anchors[:, 2] - anchors[:, 0]
anchor_heights = anchors[:, 3] - anchors[:, 1]
targets_dx1 = (gt_boxes[:, 0] - anchors[:, 0]) / anchor_widths
targets_dy1 = (gt_boxes[:, 1] - anchors[:, 1]) / anchor_heights
targets_dx2 = (gt_boxes[:, 2] - anchors[:, 2]) / anchor_widths
targets_dy2 = (gt_boxes[:, 3] - anchors[:, 3]) / anchor_heights
targets = np.stack((targets_dx1, targets_dy1, targets_dx2, targets_dy2))
targets = targets.T
targets = (targets - mean) / std
return targetsLayers
This module includes custom layers that is used by the model builder to create a RetinaNet model.
"""
Copyright 2017-2018 Fizyr (https://fizyr.com)
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
"""
# Import libraries
import numpy as np
import keras
import math
import tensorflow
import annytab.retinanet.anchors as utils_anchors
from annytab.retinanet.common import random_transform_generator, bbox_transform_inv
import annytab.retinanet.common
# Keras layer for upsampling a Tensor to be the same shape as another Tensor.
class UpsampleLike(keras.layers.Layer):
def call(self, inputs, **kwargs):
source, target = inputs
target_shape = keras.backend.shape(target)
if keras.backend.image_data_format() == 'channels_first':
source = tensorflow.transpose(source, (0, 2, 3, 1))
output = tensorflow.compat.v1.image.resize_images(source, (target_shape[2], target_shape[3]), tensorflow.image.ResizeMethod.NEAREST_NEIGHBOR, False)
output = tensorflow.transpose(output, (0, 3, 1, 2))
return output
else:
return tensorflow.compat.v1.image.resize_images(source, (target_shape[1], target_shape[2]), tensorflow.image.ResizeMethod.NEAREST_NEIGHBOR, False)
def compute_output_shape(self, input_shape):
if keras.backend.image_data_format() == 'channels_first':
return (input_shape[0][0], input_shape[0][1]) + input_shape[1][2:4]
else:
return (input_shape[0][0],) + input_shape[1][1:3] + (input_shape[0][-1],)
# Apply a prior probability to the weights
class PriorProbability(keras.initializers.Initializer):
def __init__(self, probability=0.01):
self.probability = probability
def get_config(self):
return { 'probability': self.probability }
def __call__(self, shape, dtype=None):
# set bias to -log((1 - p)/p) for foreground
result = np.ones(shape, dtype=dtype) * -math.log((1 - self.probability) / self.probability)
return result
# Keras layer for applying regression values to boxes
class RegressBoxes(keras.layers.Layer):
def __init__(self, mean=None, std=None, *args, **kwargs):
if mean is None:
mean = np.array([0, 0, 0, 0])
if std is None:
std = np.array([0.2, 0.2, 0.2, 0.2])
if isinstance(mean, (list, tuple)):
mean = np.array(mean)
elif not isinstance(mean, np.ndarray):
raise ValueError('Expected mean to be a np.ndarray, list or tuple. Received: {}'.format(type(mean)))
if isinstance(std, (list, tuple)):
std = np.array(std)
elif not isinstance(std, np.ndarray):
raise ValueError('Expected std to be a np.ndarray, list or tuple. Received: {}'.format(type(std)))
self.mean = mean
self.std = std
super(RegressBoxes, self).__init__(*args, **kwargs)
def call(self, inputs, **kwargs):
anchors, regression = inputs
return bbox_transform_inv(anchors, regression, mean=self.mean, std=self.std)
def compute_output_shape(self, input_shape):
return input_shape[0]
def get_config(self):
config = super(RegressBoxes, self).get_config()
config.update({
'mean': self.mean.tolist(),
'std' : self.std.tolist(),
})
return config
# Keras layer for filtering detections using score threshold and NMS
class FilterDetections(keras.layers.Layer):
def __init__(
self,
nms = True,
class_specific_filter = True,
nms_threshold = 0.5,
score_threshold = 0.05,
max_detections = 300,
parallel_iterations = 32,
**kwargs
):
self.nms = nms
self.class_specific_filter = class_specific_filter
self.nms_threshold = nms_threshold
self.score_threshold = score_threshold
self.max_detections = max_detections
self.parallel_iterations = parallel_iterations
super(FilterDetections, self).__init__(**kwargs)
# Constructs the NMS graph
def call(self, inputs, **kwargs):
boxes = inputs[0]
classification = inputs[1]
other = inputs[2:]
# wrap nms with our parameters
def _filter_detections(args):
boxes = args[0]
classification = args[1]
other = args[2]
return filter_detections(
boxes,
classification,
other,
nms = self.nms,
class_specific_filter = self.class_specific_filter,
score_threshold = self.score_threshold,
max_detections = self.max_detections,
nms_threshold = self.nms_threshold,
)
# call filter_detections on each batch
outputs = tensorflow.map_fn(
_filter_detections,
elems=[boxes, classification, other],
dtype=[keras.backend.floatx(), keras.backend.floatx(), 'int32'] + [o.dtype for o in other],
parallel_iterations=self.parallel_iterations
)
return outputs
# Computes the output shapes given the input shapes
def compute_output_shape(self, input_shape):
return [
(input_shape[0][0], self.max_detections, 4),
(input_shape[1][0], self.max_detections),
(input_shape[1][0], self.max_detections),
] + [
tuple([input_shape[i][0], self.max_detections] + list(input_shape[i][2:])) for i in range(2, len(input_shape))
]
# This is required in Keras when there is more than 1 output
def compute_mask(self, inputs, mask=None):
return (len(inputs) + 1) * [None]
# Gets the configuration of this layer
def get_config(self):
config = super(FilterDetections, self).get_config()
config.update({
'nms' : self.nms,
'class_specific_filter' : self.class_specific_filter,
'nms_threshold' : self.nms_threshold,
'score_threshold' : self.score_threshold,
'max_detections' : self.max_detections,
'parallel_iterations' : self.parallel_iterations,
})
return config
# Keras layer for generating achors for a given shape
class Anchors(keras.layers.Layer):
def __init__(self, size, stride, ratios=None, scales=None, *args, **kwargs):
self.size = size
self.stride = stride
self.ratios = ratios
self.scales = scales
if ratios is None:
self.ratios = common.anchor_parameters.ratios
elif isinstance(ratios, list):
self.ratios = np.array(ratios)
if scales is None:
self.scales = common.anchor_parameters.scales
elif isinstance(scales, list):
self.scales = np.array(scales)
self.num_anchors = len(ratios) * len(scales)
self.anchors = keras.backend.variable(utils_anchors.generate_anchors(
base_size=size,
ratios=ratios,
scales=scales,
))
super(Anchors, self).__init__(*args, **kwargs)
def call(self, inputs, **kwargs):
features = inputs
features_shape = keras.backend.shape(features)
# generate proposals from bbox deltas and shifted anchors
if keras.backend.image_data_format() == 'channels_first':
anchors = shift(features_shape[2:4], self.stride, self.anchors)
else:
anchors = shift(features_shape[1:3], self.stride, self.anchors)
anchors = keras.backend.tile(keras.backend.expand_dims(anchors, axis=0), (features_shape[0], 1, 1))
return anchors
def compute_output_shape(self, input_shape):
if None not in input_shape[1:]:
if keras.backend.image_data_format() == 'channels_first':
total = np.prod(input_shape[2:4]) * self.num_anchors
else:
total = np.prod(input_shape[1:3]) * self.num_anchors
return (input_shape[0], total, 4)
else:
return (input_shape[0], None, 4)
def get_config(self):
config = super(Anchors, self).get_config()
config.update({
'size' : self.size,
'stride' : self.stride,
'ratios' : self.ratios.tolist(),
'scales' : self.scales.tolist(),
})
return config
# Clip boxes
class ClipBoxes(keras.layers.Layer):
def call(self, inputs, **kwargs):
image, boxes = inputs
shape = keras.backend.cast(keras.backend.shape(image), keras.backend.floatx())
if keras.backend.image_data_format() == 'channels_first':
_, _, height, width = tensorflow.unstack(shape, axis=0)
else:
_, height, width, _ = tensorflow.unstack(shape, axis=0)
x1, y1, x2, y2 = tensorflow.unstack(boxes, axis=-1)
x1 = tensorflow.clip_by_value(x1, 0, width)
y1 = tensorflow.clip_by_value(y1, 0, height)
x2 = tensorflow.clip_by_value(x2, 0, width)
y2 = tensorflow.clip_by_value(y2, 0, height)
return keras.backend.stack([x1, y1, x2, y2], axis=2)
def compute_output_shape(self, input_shape):
return input_shape[1]
# Identical to keras.layers.BatchNormalization, but adds the option to freeze parameters.
class BatchNormalization(keras.layers.BatchNormalization):
def __init__(self, freeze, *args, **kwargs):
self.freeze = freeze
super(BatchNormalization, self).__init__(*args, **kwargs)
# set to non-trainable if freeze is true
self.trainable = not self.freeze
def call(self, *args, **kwargs):
# return super.call, but set training
return super(BatchNormalization, self).call(training=(not self.freeze), *args, **kwargs)
def get_config(self):
config = super(BatchNormalization, self).get_config()
config.update({'freeze': self.freeze})
return config
# Filter detections using the boxes and classification values
def filter_detections(boxes,classification,other= [],class_specific_filter = True,nms= True,score_threshold= 0.05,max_detections= 300,nms_threshold= 0.5):
# Threshold based on score
def _filter_detections(scores, labels):
# threshold based on score
indices = tensorflow.where(keras.backend.greater(scores, score_threshold))
if nms:
filtered_boxes = tensorflow.gather_nd(boxes, indices)
filtered_scores = keras.backend.gather(scores, indices)[:, 0]
# perform NMS
nms_indices = tensorflow.image.non_max_suppression(filtered_boxes, filtered_scores, max_output_size=max_detections, iou_threshold=nms_threshold)
# filter indices based on NMS
indices = keras.backend.gather(indices, nms_indices)
# add indices to list of all indices
labels = tensorflow.gather_nd(labels, indices)
indices = keras.backend.stack([indices[:, 0], labels], axis=1)
return indices
if class_specific_filter:
all_indices = []
# perform per class filtering
for c in range(int(classification.shape[1])):
scores = classification[:, c]
labels = c * tensorflow.ones((keras.backend.shape(scores)[0],), dtype='int64')
all_indices.append(_filter_detections(scores, labels))
# concatenate indices to single tensor
indices = keras.backend.concatenate(all_indices, axis=0)
else:
scores = keras.backend.max(classification, axis = 1)
labels = keras.backend.argmax(classification, axis = 1)
indices = _filter_detections(scores, labels)
# select top k
scores = tensorflow.gather_nd(classification, indices)
labels = indices[:, 1]
scores, top_indices = tensorflow.nn.top_k(scores, k=keras.backend.minimum(max_detections, keras.backend.shape(scores)[0]))
# filter input using the final set of indices
indices = keras.backend.gather(indices[:, 0], top_indices)
boxes = keras.backend.gather(boxes, indices)
labels = keras.backend.gather(labels, top_indices)
other_ = [keras.backend.gather(o, indices) for o in other]
# zero pad the outputs
pad_size = keras.backend.maximum(0, max_detections - keras.backend.shape(scores)[0])
boxes = tensorflow.pad(boxes, [[0, pad_size], [0, 0]], constant_values=-1)
scores = tensorflow.pad(scores, [[0, pad_size]], constant_values=-1)
labels = tensorflow.pad(labels, [[0, pad_size]], constant_values=-1)
labels = keras.backend.cast(labels, 'int32')
other_ = [tensorflow.pad(o, [[0, pad_size]] + [[0, 0] for _ in range(1, len(o.shape))], constant_values=-1) for o in other_]
# set shapes, since we know what they are
boxes.set_shape([max_detections, 4])
scores.set_shape([max_detections])
labels.set_shape([max_detections])
for o, s in zip(other_, [list(keras.backend.int_shape(o)) for o in other]):
o.set_shape([max_detections] + s[1:])
return [boxes, scores, labels] + other_
# Create a resnet 50 model
def resnet50(inputs, include_top=True, classes=1000, freeze_bn=True, numerical_names=None, *args, **kwargs):
# Create an input layer
#inputs = keras.layers.Input(shape=(None, None, 3))
# Set variables
blocks = [3, 4, 6, 3]
numerical_names = [False, False, False, False]
block = bottleneck_2d
if keras.backend.image_data_format() == "channels_last":
axis = 3
else:
axis = 1
if numerical_names is None:
numerical_names = [True] * len(blocks)
# Create layers
x = keras.layers.ZeroPadding2D(padding=3, name="padding_conv1")(inputs)
x = keras.layers.Conv2D(64, (7, 7), strides=(2, 2), use_bias=False, name="conv1")(x)
x = BatchNormalization(axis=axis, epsilon=1e-5, freeze=freeze_bn, name="bn_conv1")(x)
x = keras.layers.Activation("relu", name="conv1_relu")(x)
x = keras.layers.MaxPooling2D((3, 3), strides=(2, 2), padding="same", name="pool1")(x)
features = 64
outputs = []
# Loop blocks
for stage_id, iterations in enumerate(blocks):
for block_id in range(iterations):
x = block(features, stage_id, block_id, numerical_name=(block_id > 0 and numerical_names[stage_id]), freeze_bn=freeze_bn)(x)
features *= 2
outputs.append(x)
if include_top:
assert classes > 0
x = keras.layers.GlobalAveragePooling2D(name="pool5")(x)
x = keras.layers.Dense(classes, activation="softmax", name="fc1000")(x)
return keras.models.Model(inputs=inputs, outputs=x, *args, **kwargs)
else:
# Else output each stages features
return keras.models.Model(inputs=inputs, outputs=outputs, *args, **kwargs)
# Create a functor for computing the focal loss
def focal(alpha=0.25, gamma=2.0):
# Compute the focal loss given the target tensor and the predicted tensor
def _focal(y_true, y_pred):
# Variables
labels = y_true[:, :, :-1]
anchor_state = y_true[:, :, -1] # -1 for ignore, 0 for background, 1 for object
classification = y_pred
# filter out "ignore" anchors
indices = tensorflow.where(keras.backend.not_equal(anchor_state, -1))
labels = tensorflow.gather_nd(labels, indices)
classification = tensorflow.gather_nd(classification, indices)
# compute the focal loss
alpha_factor = keras.backend.ones_like(labels) * alpha
alpha_factor = tensorflow.where(keras.backend.equal(labels, 1), alpha_factor, 1 - alpha_factor)
focal_weight = tensorflow.where(keras.backend.equal(labels, 1), 1 - classification, classification)
focal_weight = alpha_factor * focal_weight ** gamma
cls_loss = focal_weight * keras.backend.binary_crossentropy(labels, classification)
# compute the normalizer: the number of positive anchors
normalizer = tensorflow.where(keras.backend.equal(anchor_state, 1))
normalizer = keras.backend.cast(keras.backend.shape(normalizer)[0], keras.backend.floatx())
normalizer = keras.backend.maximum(keras.backend.cast_to_floatx(1.0), normalizer)
return keras.backend.sum(cls_loss) / normalizer
return _focal
# Create a smooth L1 loss functor
def smooth_l1(sigma=3.0):
# This argument defines the point where the loss changes from L2 to L1
sigma_squared = sigma ** 2
# Compute the smooth L1 loss of y_pred w.r.t. y_true.
def _smooth_l1(y_true, y_pred):
# separate target and state
regression = y_pred
regression_target = y_true[:, :, :-1]
anchor_state = y_true[:, :, -1]
# filter out "ignore" anchors
indices = tensorflow.where(keras.backend.equal(anchor_state, 1))
regression = tensorflow.gather_nd(regression, indices)
regression_target = tensorflow.gather_nd(regression_target, indices)
# compute smooth L1 loss
# f(x) = 0.5 * (sigma * x)^2 if |x| < 1 / sigma / sigma
# |x| - 0.5 / sigma / sigma otherwise
regression_diff = regression - regression_target
regression_diff = keras.backend.abs(regression_diff)
regression_loss = tensorflow.where(
keras.backend.less(regression_diff, 1.0 / sigma_squared),
0.5 * sigma_squared * keras.backend.pow(regression_diff, 2),
regression_diff - 0.5 / sigma_squared
)
# compute the normalizer: the number of positive anchors
normalizer = keras.backend.maximum(1, keras.backend.shape(indices)[0])
normalizer = keras.backend.cast(normalizer, dtype=keras.backend.floatx())
return keras.backend.sum(regression_loss) / normalizer
return _smooth_l1
# A two-dimensional bottleneck block
def bottleneck_2d(filters, stage=0, block=0, kernel_size=3, numerical_name=False, stride=None, freeze_bn=False):
if stride is None:
if block != 0 or stage == 0:
stride = 1
else:
stride = 2
# Set parameters
parameters = { "kernel_initializer": "he_normal" }
if keras.backend.image_data_format() == "channels_last":
axis = 3
else:
axis = 1
if block > 0 and numerical_name:
block_char = "b{}".format(block)
else:
block_char = chr(ord('a') + block)
stage_char = str(stage + 2)
def f(x):
y = keras.layers.Conv2D(filters, (1, 1), strides=stride, use_bias=False, name="res{}{}_branch2a".format(stage_char, block_char), **parameters)(x)
y = BatchNormalization(axis=axis, epsilon=1e-5, freeze=freeze_bn, name="bn{}{}_branch2a".format(stage_char, block_char))(y)
y = keras.layers.Activation("relu", name="res{}{}_branch2a_relu".format(stage_char, block_char))(y)
y = keras.layers.ZeroPadding2D(padding=1, name="padding{}{}_branch2b".format(stage_char, block_char))(y)
y = keras.layers.Conv2D(filters, kernel_size, use_bias=False, name="res{}{}_branch2b".format(stage_char, block_char), **parameters)(y)
y = BatchNormalization(axis=axis, epsilon=1e-5, freeze=freeze_bn, name="bn{}{}_branch2b".format(stage_char, block_char))(y)
y = keras.layers.Activation("relu", name="res{}{}_branch2b_relu".format(stage_char, block_char))(y)
y = keras.layers.Conv2D(filters * 4, (1, 1), use_bias=False, name="res{}{}_branch2c".format(stage_char, block_char), **parameters)(y)
y = BatchNormalization(axis=axis, epsilon=1e-5, freeze=freeze_bn, name="bn{}{}_branch2c".format(stage_char, block_char))(y)
if block == 0:
shortcut = keras.layers.Conv2D(filters * 4, (1, 1), strides=stride, use_bias=False, name="res{}{}_branch1".format(stage_char, block_char), **parameters)(x)
shortcut = BatchNormalization(axis=axis, epsilon=1e-5, freeze=freeze_bn, name="bn{}{}_branch1".format(stage_char, block_char))(shortcut)
else:
shortcut = x
y = keras.layers.Add(name="res{}{}".format(stage_char, block_char))([y, shortcut])
y = keras.layers.Activation("relu", name="res{}{}_relu".format(stage_char, block_char))(y)
return y
return f
# Produce shifted anchors based on shape of the map and stride size
def shift(shape, stride, anchors):
shift_x = (keras.backend.arange(0, shape[1], dtype=keras.backend.floatx()) + keras.backend.constant(0.5, dtype=keras.backend.floatx())) * stride
shift_y = (keras.backend.arange(0, shape[0], dtype=keras.backend.floatx()) + keras.backend.constant(0.5, dtype=keras.backend.floatx())) * stride
shift_x, shift_y = tensorflow.meshgrid(shift_x, shift_y)
shift_x = keras.backend.reshape(shift_x, [-1])
shift_y = keras.backend.reshape(shift_y, [-1])
shifts = keras.backend.stack([
shift_x,
shift_y,
shift_x,
shift_y
], axis=0)
shifts = keras.backend.transpose(shifts)
number_of_anchors = keras.backend.shape(anchors)[0]
k = keras.backend.shape(shifts)[0] # number of base points = feat_h * feat_w
shifted_anchors = keras.backend.reshape(anchors, [1, number_of_anchors, 4]) + keras.backend.cast(keras.backend.reshape(shifts, [k, 1, 4]), keras.backend.floatx())
shifted_anchors = keras.backend.reshape(shifted_anchors, [k * number_of_anchors, 4])
return shifted_anchors
# Builds anchors for the shape of the features from FPN
def build_anchors(anchor_parameters, features):
anchors = [
Anchors(
size=anchor_parameters.sizes[i],
stride=anchor_parameters.strides[i],
ratios=anchor_parameters.ratios,
scales=anchor_parameters.scales,
name='anchors_{}'.format(i)
)(f) for i, f in enumerate(features)
]
return keras.layers.Concatenate(axis=1, name='anchors')(anchors)Model Builder
This module is used to create training models and inference models. A ResNet50 model is used as a backbone model for image classification, weights is preloaded from a pretrained model to speed up training time.
# Import libraries
import numpy as np
import keras
import math
import tensorflow
import annytab.retinanet.anchors as utils_anchors
import annytab.retinanet.layers as layers
import annytab.retinanet.common as common
# Get a classification model
def get_classification_model(num_classes, num_anchors, pyramid_feature_size=256, prior_probability=0.01, classification_feature_size=256):
# Create options
options = {
'kernel_size' : 3,
'strides' : 1,
'padding' : 'same',
}
# Create an input layer (Tensorflow)
inputs = keras.layers.Input(shape=(None, None, pyramid_feature_size))
# Set outputs to inputs
outputs = inputs
# Add convolution layers
for i in range(4):
outputs = keras.layers.Conv2D(
filters=classification_feature_size,
activation='relu',
name='pyramid_classification_{0}'.format(i),
kernel_initializer=keras.initializers.normal(mean=0.0, stddev=0.01, seed=None),
bias_initializer='zeros',
**options)(outputs)
# Create a convolution layer
outputs = keras.layers.Conv2D(
filters=num_classes * num_anchors,
kernel_initializer=keras.initializers.normal(mean=0.0, stddev=0.01, seed=None),
bias_initializer=layers.PriorProbability(probability=prior_probability),
name='pyramid_classification',
**options
)(outputs)
# Reshape output and apply sigmoid
if keras.backend.image_data_format() == 'channels_first':
outputs = keras.layers.Permute((2, 3, 1), name='pyramid_classification_permute')(outputs)
outputs = keras.layers.Reshape((-1, num_classes), name='pyramid_classification_reshape')(outputs)
outputs = keras.layers.Activation('sigmoid', name='pyramid_classification_sigmoid')(outputs)
# Create the classification model
model = keras.models.Model(inputs=inputs, outputs=outputs, name='classification_submodel')
# Return the classification model
return model
# Get a regression model
def get_regression_model(num_values, num_anchors, pyramid_feature_size=256, regression_feature_size=256):
# Create options
options = {
'kernel_size' : 3,
'strides' : 1,
'padding' : 'same',
'kernel_initializer' : keras.initializers.normal(mean=0.0, stddev=0.01, seed=None),
'bias_initializer' : 'zeros'
}
# Create an input layer (Tensorflow)
inputs = keras.layers.Input(shape=(None, None, pyramid_feature_size))
# Set inputs to outputs
outputs = inputs
# Create convolution layers
for i in range(4):
outputs = keras.layers.Conv2D(
filters=regression_feature_size,
activation='relu',
name='pyramid_regression_{}'.format(i),
**options
)(outputs)
outputs = keras.layers.Conv2D(num_anchors * num_values, name='pyramid_regression', **options)(outputs)
if keras.backend.image_data_format() == 'channels_first':
outputs = keras.layers.Permute((2, 3, 1), name='pyramid_regression_permute')(outputs)
outputs = keras.layers.Reshape((-1, num_values), name='pyramid_regression_reshape')(outputs)
# Return a regression model
return keras.models.Model(inputs=inputs, outputs=outputs, name='regression_submodel')
# Create pyramid featurs
def create_pyramid_features(C3, C4, C5, feature_size=256):
# upsample C5 to get P5 from the FPN paper
P5 = keras.layers.Conv2D(feature_size, kernel_size=1, strides=1, padding='same', name='C5_reduced')(C5)
P5_upsampled = layers.UpsampleLike(name='P5_upsampled')([P5, C4])
P5 = keras.layers.Conv2D(feature_size, kernel_size=3, strides=1, padding='same', name='P5')(P5)
# add P5 elementwise to C4
P4 = keras.layers.Conv2D(feature_size, kernel_size=1, strides=1, padding='same', name='C4_reduced')(C4)
P4 = keras.layers.Add(name='P4_merged')([P5_upsampled, P4])
P4_upsampled = layers.UpsampleLike(name='P4_upsampled')([P4, C3])
P4 = keras.layers.Conv2D(feature_size, kernel_size=3, strides=1, padding='same', name='P4')(P4)
# add P4 elementwise to C3
P3 = keras.layers.Conv2D(feature_size, kernel_size=1, strides=1, padding='same', name='C3_reduced')(C3)
P3 = keras.layers.Add(name='P3_merged')([P4_upsampled, P3])
P3 = keras.layers.Conv2D(feature_size, kernel_size=3, strides=1, padding='same', name='P3')(P3)
# "P6 is obtained via a 3x3 stride-2 conv on C5"
P6 = keras.layers.Conv2D(feature_size, kernel_size=3, strides=2, padding='same', name='P6')(C5)
# "P7 is computed by applying ReLU followed by a 3x3 stride-2 conv on P6"
P7 = keras.layers.Activation('relu', name='C6_relu')(P6)
P7 = keras.layers.Conv2D(feature_size, kernel_size=3, strides=2, padding='same', name='P7')(P7)
return [P3, P4, P5, P6, P7]
# Build model pyramid
def build_model_pyramid(name, model, features):
return keras.layers.Concatenate(axis=1, name=name)([model(f) for f in features])
# Build a pyramid
def build_pyramid(models, features):
return [build_model_pyramid(n, m, features) for n, m in models]
# Get training model
def get_training_model(num_classes, freeze_backbone=False):
# Get the number of anchors
num_anchors = common.anchor_parameters.num_anchors()
# Create an inputs layer to read image data [height, width, colors] (Tensorflow)
inputs = keras.layers.Input(shape=(None, None, 3))
# Get submodels
submodels = [('regression', get_regression_model(4, num_anchors)), ('classification', get_classification_model(num_classes, num_anchors))]
# Get backbone layers
resnet = layers.resnet50(inputs, include_top=False, freeze_bn=freeze_backbone)
C3, C4, C5 = resnet.outputs[1:]
# Compute pyramid features
features = create_pyramid_features(C3, C4, C5)
# For all pyramid levels, run available submodels
pyramids = build_pyramid(submodels, features)
# Return the model
return keras.models.Model(inputs=inputs, outputs=pyramids, name='retinanet')
# Get inference model
def get_inference_model(model=None, nms=True, class_specific_filter=True, **kwargs):
# Get anchor parameters
anchor_params = common.anchor_parameters
# Compute the anchors
features = [model.get_layer(p_name).output for p_name in ['P3', 'P4', 'P5', 'P6', 'P7']]
anchors = layers.build_anchors(anchor_params, features)
# We expect the anchors, regression and classification values as first output
regression = model.outputs[0]
classification = model.outputs[1]
# Any additional output from custom submodels, by default this will be []
other = model.outputs[2:]
# Apply predicted regression to anchors
boxes = layers.RegressBoxes(name='boxes')([anchors, regression])
boxes = layers.ClipBoxes(name='clipped_boxes')([model.inputs[0], boxes])
# Filter detections (apply NMS / score threshold / select top-k)
detections = layers.FilterDetections(nms= nms,class_specific_filter=class_specific_filter,name='filtered_detections')([boxes, classification] + other)
# Return the model
return keras.models.Model(inputs=model.inputs, outputs=detections, name='retinanet-bbox')Debugging
The purpose of debugging is to make sure that annotations has been specified correctly, it is important to check this before training is initiated. A generated image from debugging is shown below the code.
# Import libraries
import argparse
import os
import sys
import cv2
import random
import annytab.retinanet.csv_generator
import annytab.retinanet.anchors
import annytab.retinanet.common as common
# The main entry point for this module
def main():
# Create a transform generator
transform_generator = common.random_transform_generator(
min_rotation=-0.1,
max_rotation=0.1,
min_translation=(-0.1, -0.1),
max_translation=(0.1, 0.1),
min_shear=-0.1,
max_shear=0.1,
min_scaling=(0.9, 0.9),
max_scaling=(1.1, 1.1),
flip_x_chance=0.5,
flip_y_chance=0.5)
# Create a visual effect generator
visual_effect_generator = common.random_visual_effect_generator(
contrast_range=(0.9, 1.1),
brightness_range=(-.1, .1),
hue_range=(-0.05, 0.05),
saturation_range=(0.95, 1.05))
# Create a csv generator
generator = annytab.retinanet.csv_generator.CSVGenerator(
'C:\\DATA\\Python-data\\open-images-v5\\imgs\\train_annotations.csv',
'C:\\DATA\\Python-data\\open-images-v5\\imgs\\classes.csv',
transform_generator=transform_generator,
visual_effect_generator=visual_effect_generator,
no_resize = True)
# Get anchor paramters
anchor_params = common.anchor_parameters
# Loop images
i = random.randint(0, generator.size())
count = 0
while True:
# Get the image
image = generator.load_image(i)
# Get annotations
annotations = generator.load_annotations(i)
# Make sure that there is labels
if len(annotations['labels']) > 0:
# Apply random transformations
#image, annotations = generator.random_transform_group_entry(image, annotations)
#image, annotations = generator.random_visual_effect_group_entry(image, annotations)
# Get anchors
anchors = annytab.retinanet.anchors.anchors_for_shape(image.shape, anchor_params=anchor_params)
positive_indices, _, max_indices = annytab.retinanet.anchors.compute_gt_annotations(anchors, annotations['bboxes'])
# Draw anchors on the image
common.draw_boxes(image, anchors[positive_indices], (255, 255, 0), thickness=1)
# Draw annotations
common.draw_annotations(image, annotations, color=(0, 0, 255), label_to_name=generator.label_to_name)
# Draw regressed anchors in green to override most red annotations
# result is that annotations without anchors are red, with anchors are green
common.draw_boxes(image, annotations['bboxes'][max_indices[positive_indices], :], (0, 255, 0))
# Write to a file
cv2.imwrite('C:\\DATA\\Python-data\\open-images-v5\\retinanet\\debug\\' + str(count) + '.jpg', image)
# Continue if there is more images, limit debugging to 20 images
i = 0 if i == generator.size() else i + 1
count += 1
if count >= 20:
break
else:
continue
# Tell python to run main method
if __name__ == "__main__": main()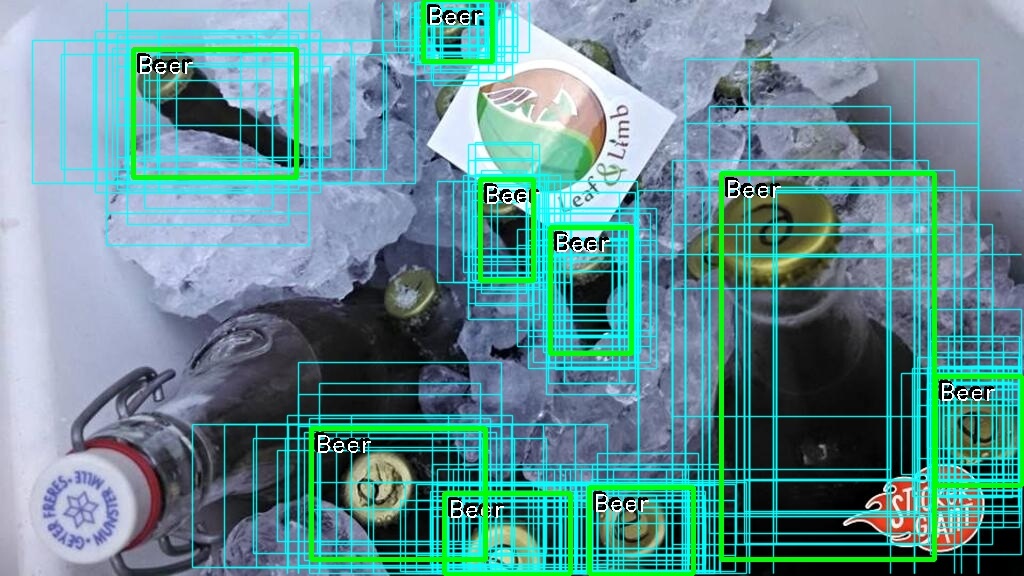
Training
Training models is created if no training has been done before, weights can be loaded from a pretrained model. Training models is loaded with saved weights if training has been conducted before, this enables the model to continue training (transfer learning). The result from a run is shown below the code.
# Import libraries
import os
import keras
import numpy as np
import annytab.retinanet.csv_generator
import annytab.retinanet.model_builder as mb
import annytab.retinanet.layers as layers
import annytab.retinanet.common as common
# Train
def train():
# Set the gpu to use
common.setup_gpu('cpu')
# Custom objects
custom_layers = {
'UpsampleLike' : layers.UpsampleLike,
'PriorProbability' : layers.PriorProbability,
'RegressBoxes' : layers.RegressBoxes,
'FilterDetections' : layers.FilterDetections,
'Anchors' : layers.Anchors,
'ClipBoxes' : layers.ClipBoxes,
'_smooth_l1' : layers.smooth_l1(),
'_focal' : layers.focal(),
'BatchNormalization' : layers.BatchNormalization}
# Create a transform generator
transform_generator = common.random_transform_generator(
min_rotation=-0.1,
max_rotation=0.1,
min_translation=(-0.1, -0.1),
max_translation=(0.1, 0.1),
min_shear=-0.1,
max_shear=0.1,
min_scaling=(0.9, 0.9),
max_scaling=(1.1, 1.1),
flip_x_chance=0.5,
flip_y_chance=0.5)
# Create a visual effect generator
visual_effect_generator = common.random_visual_effect_generator(
contrast_range=(0.9, 1.1),
brightness_range=(-.1, .1),
hue_range=(-0.05, 0.05),
saturation_range=(0.95, 1.05)
)
# Set options
common_options = {
'batch_size' : 1,
'shuffle_groups' : True,
'image_min_side' : 300,
'image_max_side' : 800,
'no_resize' : False,
'preprocess_image' : common.preprocess_image}
# Create a train generator
train_generator = annytab.retinanet.csv_generator.CSVGenerator(
'C:\\DATA\\Python-data\\open-images-v5\\imgs\\train_annotations.csv',
'C:\\DATA\\Python-data\\open-images-v5\\imgs\\classes.csv',
transform_generator=None,
visual_effect_generator=None,
**common_options)
# Get a training model
if(os.path.isfile('C:\\DATA\\Python-data\\open-images-v5\\retinanet\\training_model.h5') == True):
training_model = keras.models.load_model('C:\\DATA\\Python-data\\open-images-v5\\retinanet\\training_model.h5', custom_objects=custom_layers)
else:
training_model = mb.get_training_model(train_generator.num_classes(), True)
training_model.compile(loss={'regression' : layers.smooth_l1(), 'classification' : layers.focal() },
optimizer=keras.optimizers.adam(lr=1e-5, clipnorm=0.001))
# Plot training model
#keras.utils.plot_model(training_model, show_shapes=True, to_file='C:\\DATA\\Python-data\\open-images-v5\\retinanet\\plots\\training_model.png')
# Start training
training_model.fit_generator(
generator=train_generator,
steps_per_epoch=480, # 480 images (epoch_length)
epochs=4, # 40 so far
verbose=1,
max_queue_size=2)
# Save the training model
training_model.save('C:\\DATA\\Python-data\\open-images-v5\\retinanet\\training_model.h5')
# Get inference model
inference_model = mb.get_inference_model(model=training_model, nms=True, class_specific_filter=True)
# Save the inference model
inference_model.save('C:\\DATA\\Python-data\\open-images-v5\\retinanet\\inference_model.h5')
# The main entry point for this module
def main():
# Start training
train()
# Tell python to run main method
if __name__ == "__main__": main()351/480 [====================>.........] - ETA: 3:04 - loss: 0.8706 - regression_loss: 0.6824 - classification_loss: 0.1882
352/480 [=====================>........] - ETA: 3:03 - loss: 0.8690 - regression_loss: 0.6812 - classification_loss: 0.1878
353/480 [=====================>........] - ETA: 3:01 - loss: 0.8681 - regression_loss: 0.6806 - classification_loss: 0.1875
354/480 [=====================>........] - ETA: 3:00 - loss: 0.8685 - regression_loss: 0.6811 - classification_loss: 0.1874
355/480 [=====================>........] - ETA: 2:59 - loss: 0.8677 - regression_loss: 0.6806 - classification_loss: 0.1871
356/480 [=====================>........] - ETA: 2:57 - loss: 0.8685 - regression_loss: 0.6812 - classification_loss: 0.1873
357/480 [=====================>........] - ETA: 2:56 - loss: 0.8677 - regression_loss: 0.6804 - classification_loss: 0.1873
358/480 [=====================>........] - ETA: 2:54 - loss: 0.8673 - regression_loss: 0.6798 - classification_loss: 0.1875
359/480 [=====================>........] - ETA: 2:53 - loss: 0.8668 - regression_loss: 0.6795 - classification_loss: 0.1873
360/480 [=====================>........] - ETA: 2:52 - loss: 0.8674 - regression_loss: 0.6798 - classification_loss: 0.1876
361/480 [=====================>........] - ETA: 2:50 - loss: 0.8678 - regression_loss: 0.6802 - classification_loss: 0.1876
362/480 [=====================>........] - ETA: 2:49 - loss: 0.8694 - regression_loss: 0.6813 - classification_loss: 0.1881
363/480 [=====================>........] - ETA: 2:47 - loss: 0.8697 - regression_loss: 0.6815 - classification_loss: 0.1882
364/480 [=====================>........] - ETA: 2:46 - loss: 0.8689 - regression_loss: 0.6809 - classification_loss: 0.1880
365/480 [=====================>........] - ETA: 2:45 - loss: 0.8682 - regression_loss: 0.6805 - classification_loss: 0.1878
366/480 [=====================>........] - ETA: 2:43 - loss: 0.8688 - regression_loss: 0.6808 - classification_loss: 0.1880
367/480 [=====================>........] - ETA: 2:42 - loss: 0.8678 - regression_loss: 0.6801 - classification_loss: 0.1877
368/480 [======================>.......] - ETA: 2:40 - loss: 0.8675 - regression_loss: 0.6798 - classification_loss: 0.1876
369/480 [======================>.......] - ETA: 2:39 - loss: 0.8687 - regression_loss: 0.6807 - classification_loss: 0.1879
370/480 [======================>.......] - ETA: 2:38 - loss: 0.8682 - regression_loss: 0.6805 - classification_loss: 0.1877
371/480 [======================>.......] - ETA: 2:36 - loss: 0.8664 - regression_loss: 0.6791 - classification_loss: 0.1873
372/480 [======================>.......] - ETA: 2:35 - loss: 0.8660 - regression_loss: 0.6789 - classification_loss: 0.1871
373/480 [======================>.......] - ETA: 2:33 - loss: 0.8643 - regression_loss: 0.6771 - classification_loss: 0.1872
374/480 [======================>.......] - ETA: 2:32 - loss: 0.8639 - regression_loss: 0.6769 - classification_loss: 0.1870
375/480 [======================>.......] - ETA: 2:30 - loss: 0.8636 - regression_loss: 0.6764 - classification_loss: 0.1872
376/480 [======================>.......] - ETA: 2:29 - loss: 0.8646 - regression_loss: 0.6769 - classification_loss: 0.1877
377/480 [======================>.......] - ETA: 2:28 - loss: 0.8631 - regression_loss: 0.6757 - classification_loss: 0.1874
378/480 [======================>.......] - ETA: 2:26 - loss: 0.8646 - regression_loss: 0.6767 - classification_loss: 0.1879
379/480 [======================>.......] - ETA: 2:25 - loss: 0.8661 - regression_loss: 0.6780 - classification_loss: 0.1881
380/480 [======================>.......] - ETA: 2:24 - loss: 0.8679 - regression_loss: 0.6793 - classification_loss: 0.1887
381/480 [======================>.......] - ETA: 2:22 - loss: 0.8674 - regression_loss: 0.6791 - classification_loss: 0.1884
382/480 [======================>.......] - ETA: 2:21 - loss: 0.8684 - regression_loss: 0.6795 - classification_loss: 0.1890
383/480 [======================>.......] - ETA: 2:19 - loss: 0.8688 - regression_loss: 0.6798 - classification_loss: 0.1891
384/480 [=======================>......] - ETA: 2:18 - loss: 0.8692 - regression_loss: 0.6802 - classification_loss: 0.1890
385/480 [=======================>......] - ETA: 2:17 - loss: 0.8704 - regression_loss: 0.6812 - classification_loss: 0.1892
386/480 [=======================>......] - ETA: 2:15 - loss: 0.8702 - regression_loss: 0.6809 - classification_loss: 0.1893
387/480 [=======================>......] - ETA: 2:14 - loss: 0.8699 - regression_loss: 0.6808 - classification_loss: 0.1892
388/480 [=======================>......] - ETA: 2:12 - loss: 0.8716 - regression_loss: 0.6823 - classification_loss: 0.1893
389/480 [=======================>......] - ETA: 2:11 - loss: 0.8725 - regression_loss: 0.6829 - classification_loss: 0.1897
390/480 [=======================>......] - ETA: 2:09 - loss: 0.8718 - regression_loss: 0.6822 - classification_loss: 0.1896
391/480 [=======================>......] - ETA: 2:08 - loss: 0.8747 - regression_loss: 0.6842 - classification_loss: 0.1905
392/480 [=======================>......] - ETA: 2:07 - loss: 0.8742 - regression_loss: 0.6839 - classification_loss: 0.1902
393/480 [=======================>......] - ETA: 2:05 - loss: 0.8751 - regression_loss: 0.6842 - classification_loss: 0.1910
394/480 [=======================>......] - ETA: 2:04 - loss: 0.8761 - regression_loss: 0.6851 - classification_loss: 0.1911
395/480 [=======================>......] - ETA: 2:02 - loss: 0.8757 - regression_loss: 0.6849 - classification_loss: 0.1908
396/480 [=======================>......] - ETA: 2:01 - loss: 0.8765 - regression_loss: 0.6855 - classification_loss: 0.1910
397/480 [=======================>......] - ETA: 2:00 - loss: 0.8766 - regression_loss: 0.6857 - classification_loss: 0.1909
398/480 [=======================>......] - ETA: 1:58 - loss: 0.8765 - regression_loss: 0.6856 - classification_loss: 0.1909
399/480 [=======================>......] - ETA: 1:57 - loss: 0.8761 - regression_loss: 0.6854 - classification_loss: 0.1907
400/480 [========================>.....] - ETA: 1:55 - loss: 0.8756 - regression_loss: 0.6851 - classification_loss: 0.1905
401/480 [========================>.....] - ETA: 1:54 - loss: 0.8752 - regression_loss: 0.6848 - classification_loss: 0.1904
402/480 [========================>.....] - ETA: 1:52 - loss: 0.8743 - regression_loss: 0.6842 - classification_loss: 0.1901
403/480 [========================>.....] - ETA: 1:51 - loss: 0.8745 - regression_loss: 0.6845 - classification_loss: 0.1900
404/480 [========================>.....] - ETA: 1:50 - loss: 0.8741 - regression_loss: 0.6844 - classification_loss: 0.1897
405/480 [========================>.....] - ETA: 1:48 - loss: 0.8736 - regression_loss: 0.6841 - classification_loss: 0.1894
406/480 [========================>.....] - ETA: 1:47 - loss: 0.8738 - regression_loss: 0.6844 - classification_loss: 0.1894
407/480 [========================>.....] - ETA: 1:45 - loss: 0.8747 - regression_loss: 0.6851 - classification_loss: 0.1896
408/480 [========================>.....] - ETA: 1:44 - loss: 0.8743 - regression_loss: 0.6849 - classification_loss: 0.1893
409/480 [========================>.....] - ETA: 1:42 - loss: 0.8751 - regression_loss: 0.6857 - classification_loss: 0.1894
410/480 [========================>.....] - ETA: 1:41 - loss: 0.8744 - regression_loss: 0.6850 - classification_loss: 0.1893
411/480 [========================>.....] - ETA: 1:40 - loss: 0.8738 - regression_loss: 0.6847 - classification_loss: 0.1891
412/480 [========================>.....] - ETA: 1:38 - loss: 0.8736 - regression_loss: 0.6846 - classification_loss: 0.1890
413/480 [========================>.....] - ETA: 1:37 - loss: 0.8742 - regression_loss: 0.6852 - classification_loss: 0.1890
414/480 [========================>.....] - ETA: 1:35 - loss: 0.8737 - regression_loss: 0.6850 - classification_loss: 0.1888
415/480 [========================>.....] - ETA: 1:34 - loss: 0.8740 - regression_loss: 0.6852 - classification_loss: 0.1888
416/480 [=========================>....] - ETA: 1:32 - loss: 0.8755 - regression_loss: 0.6864 - classification_loss: 0.1890
417/480 [=========================>....] - ETA: 1:31 - loss: 0.8756 - regression_loss: 0.6866 - classification_loss: 0.1891
418/480 [=========================>....] - ETA: 1:29 - loss: 0.8760 - regression_loss: 0.6868 - classification_loss: 0.1892
419/480 [=========================>....] - ETA: 1:28 - loss: 0.8750 - regression_loss: 0.6861 - classification_loss: 0.1889
420/480 [=========================>....] - ETA: 1:27 - loss: 0.8762 - regression_loss: 0.6868 - classification_loss: 0.1893
421/480 [=========================>....] - ETA: 1:25 - loss: 0.8768 - regression_loss: 0.6874 - classification_loss: 0.1894
422/480 [=========================>....] - ETA: 1:24 - loss: 0.8767 - regression_loss: 0.6870 - classification_loss: 0.1896
423/480 [=========================>....] - ETA: 1:22 - loss: 0.8768 - regression_loss: 0.6871 - classification_loss: 0.1896
424/480 [=========================>....] - ETA: 1:21 - loss: 0.8763 - regression_loss: 0.6867 - classification_loss: 0.1896
425/480 [=========================>....] - ETA: 1:19 - loss: 0.8765 - regression_loss: 0.6869 - classification_loss: 0.1896
426/480 [=========================>....] - ETA: 1:18 - loss: 0.8776 - regression_loss: 0.6879 - classification_loss: 0.1897
427/480 [=========================>....] - ETA: 1:17 - loss: 0.8767 - regression_loss: 0.6873 - classification_loss: 0.1894
428/480 [=========================>....] - ETA: 1:15 - loss: 0.8760 - regression_loss: 0.6867 - classification_loss: 0.1893
429/480 [=========================>....] - ETA: 1:14 - loss: 0.8762 - regression_loss: 0.6868 - classification_loss: 0.1894
430/480 [=========================>....] - ETA: 1:12 - loss: 0.8774 - regression_loss: 0.6878 - classification_loss: 0.1896
431/480 [=========================>....] - ETA: 1:11 - loss: 0.8774 - regression_loss: 0.6879 - classification_loss: 0.1895
432/480 [==========================>...] - ETA: 1:09 - loss: 0.8772 - regression_loss: 0.6877 - classification_loss: 0.1895
433/480 [==========================>...] - ETA: 1:08 - loss: 0.8767 - regression_loss: 0.6875 - classification_loss: 0.1892
434/480 [==========================>...] - ETA: 1:06 - loss: 0.8774 - regression_loss: 0.6879 - classification_loss: 0.1895
435/480 [==========================>...] - ETA: 1:05 - loss: 0.8778 - regression_loss: 0.6884 - classification_loss: 0.1894
436/480 [==========================>...] - ETA: 1:03 - loss: 0.8778 - regression_loss: 0.6886 - classification_loss: 0.1892
437/480 [==========================>...] - ETA: 1:02 - loss: 0.8784 - regression_loss: 0.6893 - classification_loss: 0.1891
438/480 [==========================>...] - ETA: 1:01 - loss: 0.8775 - regression_loss: 0.6887 - classification_loss: 0.1888
439/480 [==========================>...] - ETA: 59s - loss: 0.8773 - regression_loss: 0.6886 - classification_loss: 0.1886
440/480 [==========================>...] - ETA: 58s - loss: 0.8772 - regression_loss: 0.6886 - classification_loss: 0.1886
441/480 [==========================>...] - ETA: 56s - loss: 0.8778 - regression_loss: 0.6892 - classification_loss: 0.1886
442/480 [==========================>...] - ETA: 55s - loss: 0.8779 - regression_loss: 0.6894 - classification_loss: 0.1885
443/480 [==========================>...] - ETA: 53s - loss: 0.8787 - regression_loss: 0.6905 - classification_loss: 0.1882
444/480 [==========================>...] - ETA: 52s - loss: 0.8800 - regression_loss: 0.6913 - classification_loss: 0.1887
445/480 [==========================>...] - ETA: 50s - loss: 0.8802 - regression_loss: 0.6914 - classification_loss: 0.1888
446/480 [==========================>...] - ETA: 49s - loss: 0.8812 - regression_loss: 0.6924 - classification_loss: 0.1888
447/480 [==========================>...] - ETA: 47s - loss: 0.8816 - regression_loss: 0.6928 - classification_loss: 0.1888
448/480 [===========================>..] - ETA: 46s - loss: 0.8829 - regression_loss: 0.6939 - classification_loss: 0.1890
449/480 [===========================>..] - ETA: 45s - loss: 0.8843 - regression_loss: 0.6950 - classification_loss: 0.1893
450/480 [===========================>..] - ETA: 43s - loss: 0.8844 - regression_loss: 0.6951 - classification_loss: 0.1893
451/480 [===========================>..] - ETA: 42s - loss: 0.8852 - regression_loss: 0.6959 - classification_loss: 0.1892
452/480 [===========================>..] - ETA: 40s - loss: 0.8853 - regression_loss: 0.6961 - classification_loss: 0.1892
453/480 [===========================>..] - ETA: 39s - loss: 0.8855 - regression_loss: 0.6961 - classification_loss: 0.1894
454/480 [===========================>..] - ETA: 37s - loss: 0.8853 - regression_loss: 0.6958 - classification_loss: 0.1895
455/480 [===========================>..] - ETA: 36s - loss: 0.8854 - regression_loss: 0.6958 - classification_loss: 0.1896
456/480 [===========================>..] - ETA: 34s - loss: 0.8846 - regression_loss: 0.6952 - classification_loss: 0.1895
457/480 [===========================>..] - ETA: 33s - loss: 0.8837 - regression_loss: 0.6945 - classification_loss: 0.1892
458/480 [===========================>..] - ETA: 32s - loss: 0.8841 - regression_loss: 0.6946 - classification_loss: 0.1895
459/480 [===========================>..] - ETA: 30s - loss: 0.8846 - regression_loss: 0.6943 - classification_loss: 0.1903
460/480 [===========================>..] - ETA: 29s - loss: 0.8840 - regression_loss: 0.6938 - classification_loss: 0.1901
461/480 [===========================>..] - ETA: 27s - loss: 0.8837 - regression_loss: 0.6937 - classification_loss: 0.1899
462/480 [===========================>..] - ETA: 26s - loss: 0.8826 - regression_loss: 0.6930 - classification_loss: 0.1896
463/480 [===========================>..] - ETA: 24s - loss: 0.8824 - regression_loss: 0.6928 - classification_loss: 0.1896
464/480 [============================>.] - ETA: 23s - loss: 0.8821 - regression_loss: 0.6925 - classification_loss: 0.1896
465/480 [============================>.] - ETA: 21s - loss: 0.8808 - regression_loss: 0.6915 - classification_loss: 0.1893
466/480 [============================>.] - ETA: 20s - loss: 0.8818 - regression_loss: 0.6924 - classification_loss: 0.1894
467/480 [============================>.] - ETA: 18s - loss: 0.8818 - regression_loss: 0.6926 - classification_loss: 0.1892
468/480 [============================>.] - ETA: 17s - loss: 0.8811 - regression_loss: 0.6920 - classification_loss: 0.1890
469/480 [============================>.] - ETA: 16s - loss: 0.8820 - regression_loss: 0.6928 - classification_loss: 0.1891
470/480 [============================>.] - ETA: 14s - loss: 0.8824 - regression_loss: 0.6931 - classification_loss: 0.1893
471/480 [============================>.] - ETA: 13s - loss: 0.8837 - regression_loss: 0.6943 - classification_loss: 0.1894
472/480 [============================>.] - ETA: 11s - loss: 0.8844 - regression_loss: 0.6949 - classification_loss: 0.1895
473/480 [============================>.] - ETA: 10s - loss: 0.8849 - regression_loss: 0.6952 - classification_loss: 0.1898
474/480 [============================>.] - ETA: 8s - loss: 0.8857 - regression_loss: 0.6956 - classification_loss: 0.1901
475/480 [============================>.] - ETA: 7s - loss: 0.8851 - regression_loss: 0.6951 - classification_loss: 0.1900
476/480 [============================>.] - ETA: 5s - loss: 0.8845 - regression_loss: 0.6947 - classification_loss: 0.1898
477/480 [============================>.] - ETA: 4s - loss: 0.8839 - regression_loss: 0.6942 - classification_loss: 0.1897
478/480 [============================>.] - ETA: 2s - loss: 0.8836 - regression_loss: 0.6939 - classification_loss: 0.1897
479/480 [============================>.] - ETA: 1s - loss: 0.8839 - regression_loss: 0.6942 - classification_loss: 0.1897
480/480 [==============================] - 702s 1s/step - loss: 0.8850 - regression_loss: 0.6950 - classification_loss: 0.1900Evaluation
This module is used to perform visual evaluation of the model. I have only trained the model in 40 epochs, this type of models needs a lot of training to perform well. I have set the score threshold to 40 % and the maximum number of detections to 10. The result from an evaluation is shown below the code.
# Import libraries
import os
import sys
import cv2
import keras
import numpy as np
import progressbar
assert(callable(progressbar.progressbar)), "Using wrong progressbar module, install 'progressbar2' instead."
import annytab.retinanet.csv_generator
import annytab.retinanet.anchors
import annytab.retinanet.model_builder as mb
import annytab.retinanet.layers as layers
import annytab.retinanet.common as common
# Compute the average precision, given the recall and precision curves
def _compute_ap(recall, precision):
# correct AP calculation
# first append sentinel values at the end
mrec = np.concatenate(([0.], recall, [1.]))
mpre = np.concatenate(([0.], precision, [0.]))
# compute the precision envelope
for i in range(mpre.size - 1, 0, -1):
mpre[i - 1] = np.maximum(mpre[i - 1], mpre[i])
# to calculate area under PR curve, look for points
# where X axis (recall) changes value
i = np.where(mrec[1:] != mrec[:-1])[0]
# and sum (\Delta recall) * prec
ap = np.sum((mrec[i + 1] - mrec[i]) * mpre[i + 1])
return ap
# Get the detections from the model using the generator
def _get_detections(generator, model, score_threshold=0.05, max_detections=100, save_path=None):
all_detections = [[None for i in range(generator.num_classes()) if generator.has_label(i)] for j in range(generator.size())]
for i in progressbar.progressbar(range(generator.size()), prefix='Running network: '):
raw_image = generator.load_image(i)
image = generator.preprocess_image(raw_image.copy())
image, scale = generator.resize_image(image)
if keras.backend.image_data_format() == 'channels_first':
image = image.transpose((2, 0, 1))
# Run network
boxes, scores, labels = model.predict_on_batch(np.expand_dims(image, axis=0))[:3]
# Correct boxes for image scale
boxes /= scale
# Select indices which have a score above the threshold
indices = np.where(scores[0, :] > score_threshold)[0]
# Select those scores
scores = scores[0][indices]
# Find the order with which to sort the scores
scores_sort = np.argsort(-scores)[:max_detections]
# Select detections
image_boxes = boxes[0, indices[scores_sort], :]
image_scores = scores[scores_sort]
image_labels = labels[0, indices[scores_sort]]
image_detections = np.concatenate([image_boxes, np.expand_dims(image_scores, axis=1), np.expand_dims(image_labels, axis=1)], axis=1)
# Save image to disk
if save_path is not None:
#common.draw_annotations(raw_image, generator.load_annotations(i), label_to_name=generator.label_to_name)
common.draw_detections(raw_image, image_boxes, image_scores, image_labels, label_to_name=generator.label_to_name, score_threshold=score_threshold)
cv2.imwrite(os.path.join(save_path, '{}.png'.format(i)), raw_image)
# Copy detections to all_detections
for label in range(generator.num_classes()):
if not generator.has_label(label):
continue
all_detections[i][label] = image_detections[image_detections[:, -1] == label, :-1]
return all_detections
# Get the ground truth annotations from the generator
def _get_annotations(generator):
all_annotations = [[None for i in range(generator.num_classes())] for j in range(generator.size())]
for i in progressbar.progressbar(range(generator.size()), prefix='Parsing annotations: '):
# load the annotations
annotations = generator.load_annotations(i)
# copy detections to all_annotations
for label in range(generator.num_classes()):
if not generator.has_label(label):
continue
all_annotations[i][label] = annotations['bboxes'][annotations['labels'] == label, :].copy()
return all_annotations
# Evaluate a given dataset using a given model
def evaluate(generator, model, iou_threshold=0.5, score_threshold=0.05, max_detections=100, save_path=None):
# gather all detections and annotations
all_detections = _get_detections(generator, model, score_threshold=score_threshold, max_detections=max_detections, save_path=save_path)
all_annotations = _get_annotations(generator)
average_precisions = {}
# process detections and annotations
for label in range(generator.num_classes()):
if not generator.has_label(label):
continue
false_positives = np.zeros((0,))
true_positives = np.zeros((0,))
scores = np.zeros((0,))
num_annotations = 0.0
for i in range(generator.size()):
detections = all_detections[i][label]
annotations = all_annotations[i][label]
num_annotations += annotations.shape[0]
detected_annotations = []
for d in detections:
scores = np.append(scores, d[4])
if annotations.shape[0] == 0:
false_positives = np.append(false_positives, 1)
true_positives = np.append(true_positives, 0)
continue
overlaps = annytab.retinanet.anchors.compute_overlap(np.expand_dims(d, axis=0), annotations)
assigned_annotation = np.argmax(overlaps, axis=1)
max_overlap = overlaps[0, assigned_annotation]
if max_overlap >= iou_threshold and assigned_annotation not in detected_annotations:
false_positives = np.append(false_positives, 0)
true_positives = np.append(true_positives, 1)
detected_annotations.append(assigned_annotation)
else:
false_positives = np.append(false_positives, 1)
true_positives = np.append(true_positives, 0)
# no annotations -> AP for this class is 0 (is this correct?)
if num_annotations == 0:
average_precisions[label] = 0, 0
continue
# sort by score
indices = np.argsort(-scores)
false_positives = false_positives[indices]
true_positives = true_positives[indices]
# compute false positives and true positives
false_positives = np.cumsum(false_positives)
true_positives = np.cumsum(true_positives)
# compute recall and precision
recall = true_positives / num_annotations
precision = true_positives / np.maximum(true_positives + false_positives, np.finfo(np.float64).eps)
# compute average precision
average_precision = _compute_ap(recall, precision)
average_precisions[label] = average_precision, num_annotations
return average_precisions
# The main entry point for this module
def main():
# Set the gpu to use
common.setup_gpu('cpu')
# Create a test generator
test_generator = annytab.retinanet.csv_generator.CSVGenerator(
'C:\\DATA\\Python-data\\open-images-v5\\imgs\\test_annotations.csv',
'C:\\DATA\\Python-data\\open-images-v5\\imgs\\classes.csv',
image_min_side=300,
image_max_side=800,
shuffle_groups=True)
# Load a model
print('Loading model, this may take a second...')
# Custom objects
custom_layers = {
'UpsampleLike' : layers.UpsampleLike,
'PriorProbability' : layers.PriorProbability,
'RegressBoxes' : layers.RegressBoxes,
'FilterDetections' : layers.FilterDetections,
'Anchors' : layers.Anchors,
'ClipBoxes' : layers.ClipBoxes,
'_smooth_l1' : layers.smooth_l1(),
'_focal' : layers.focal(),
'BatchNormalization' : layers.BatchNormalization}
# Get a model
model = keras.models.load_model('C:\\DATA\\Python-data\\open-images-v5\\retinanet\\inference_model.h5', custom_objects=custom_layers)
# Start evaluations
average_precisions = evaluate(test_generator, model, iou_threshold=0.5, score_threshold=0.4, max_detections=10, save_path='C:\\DATA\\Python-data\\open-images-v5\\retinanet\\evaluation\\')
# Print evaluation
total_instances = []
precisions = []
for label, (average_precision, num_annotations) in average_precisions.items():
print('{:.0f} instances of class'.format(num_annotations), test_generator.label_to_name(label), 'with average precision: {0:.4f}'.format(average_precision))
total_instances.append(num_annotations)
precisions.append(average_precision)
if sum(total_instances) == 0:
print('No test instances found.')
else:
print('mAP using the weighted average of precisions among classes: {0:.4f}'.format(sum([a * b for a, b in zip(total_instances, precisions)]) / sum(total_instances)))
print('mAP: {0:.4f}'.format(sum(precisions) / sum(x > 0 for x in total_instances)))
# Tell python to run main method
if __name__ == "__main__": main()