I am going to perform fasttext classification of texts in the 20 Newsgroups dataset in this tutorial. I am going to use Keras in Python to build the model. I am going to visualize the dataset, train the model and evaluate the performance of the model.
Fasttext is developed by Facebook and exists as an open source project on GitHub. Fasttext is a neural network model that is used for text classification, it supports supervised learning and unsupervised learning. Text classification is a task that is supposed to classify texts in 2 or more categories.
Dataset and Libraries
I am using the 20 Newsgroups dataset (download it) in this tutorial. You should download 20news-bydate.tar.gz, this data set is sorted by date and divided into a training set and a test set. Unpack the file to a folder (20news_bydate), files is divided into folders where the name of the folder represent the name of a category. I have used the following libraries: os, re, string, numpy, nltk, pickle, contextlib, matplotlib, scikit-learn and keras.
Visualize Dataset
The code to visualize the dataset is included in the training module. We mainly want to see the balance of the training set, a balanced dataset is important in classification algorithms. The dataset is not perfectly balanced, the most frequent category (rec.sport.hockey) have 600 articles and the least frequent category (talk.religion.misc) have 377 articles. The probability of correctly predicting the most frequent category at random is 5.3 % (600 *100/11314), our model needs to have a higher probability than this to be useful.
--- Information ---
Number of articles: 11314
Number of categories: 20
--- Class distribution ---
alt.atheism: 480
comp.graphics: 584
comp.os.ms-windows.misc: 591
comp.sys.ibm.pc.hardware: 590
comp.sys.mac.hardware: 578
comp.windows.x: 593
misc.forsale: 585
rec.autos: 594
rec.motorcycles: 598
rec.sport.baseball: 597
rec.sport.hockey: 600
sci.crypt: 595
sci.electronics: 591
sci.med: 594
sci.space: 593
soc.religion.christian: 599
talk.politics.guns: 546
talk.politics.mideast: 564
talk.politics.misc: 465
talk.religion.misc: 377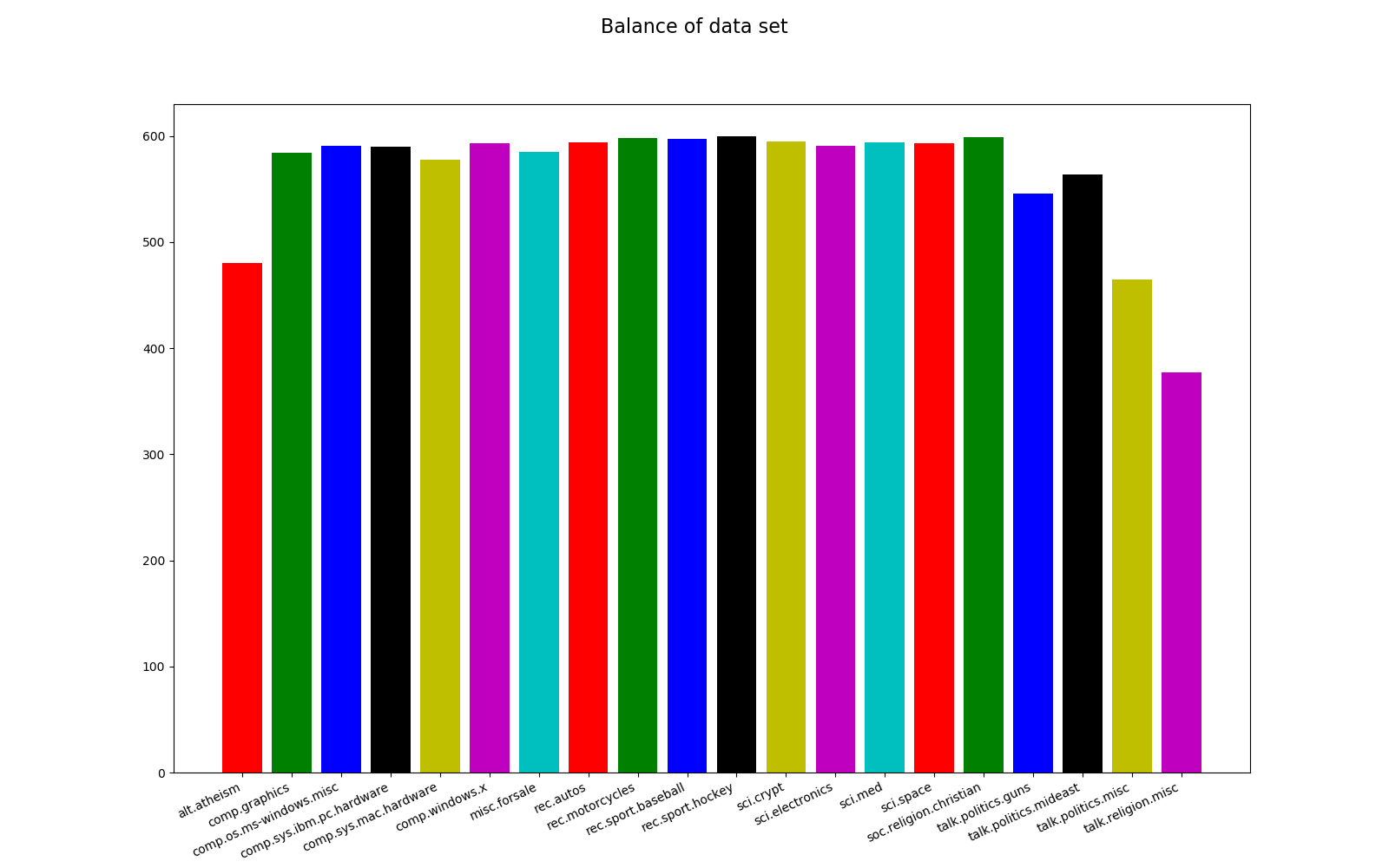
Common Module
I have created a common module (common.py) with configuration, functions to preprocess data and a function to build the fasttext model. The preprocessing method will remove headers, footers, quotes, punctations and digits for each article in the dataset. I am also using a stemmer to stem each word in each article, this process takes some time and you may want to comment this line to speed things up. You can use a lemmatizer instead of a stemmer if you want, you might need to download WordNetLemmatizer. This module also includes two methods to create n-grams.
# Import libraries
import re
import string
import keras
import keras.preprocessing
import contextlib
import nltk.stem
# Download WordNetLemmatizer
# nltk.download()
# Variables
QUOTES = re.compile(r'(writes in|writes:|wrote:|says:|said:|^In article|^Quoted from|^\||^>)')
# Configuration
class Configuration:
# Initializes the class
def __init__(self):
self.ngram_range = 2
self.num_words = 20000 # Size of vocabulary, max number of words in a document
self.max_length = 1000 # The maximum number of words in any document
self.num_classes = 20
self.batch_size = 32
self.embedding_dims = 50
self.epochs = 40 # 140 so far
# Preprocess data
def preprocess_data(data):
# Create a stemmer/lemmatizer
stemmer = nltk.stem.SnowballStemmer('english')
#lemmer = nltk.stem.WordNetLemmatizer()
for i in range(len(data)):
# Remove header
_, _, data[i] = data[i].partition('\n\n')
# Remove footer
lines = data[i].strip().split('\n')
for line_num in range(len(lines) - 1, -1, -1):
line = lines[line_num]
if line.strip().strip('-') == '':
break
if line_num > 0:
data[i] = '\n'.join(lines[:line_num])
# Remove quotes
data[i] = '\n'.join([line for line in data[i].split('\n') if not QUOTES.search(line)])
# Remove punctation (!"#$%&'()*+,-./:;<=>?@[\]^_`{|}~)
data[i] = data[i].translate(str.maketrans('', '', string.punctuation))
# Remove digits
data[i] = re.sub('\d', '', data[i])
# Stem words
data[i] = ' '.join([stemmer.stem(word) for word in data[i].split()])
#data[i] = ' '.join([lemmer.lemmatize(word) for word in data[i].split()])
# Return data
return data
# Create n-gram set, extract a set of n-grams from a list of integers
def create_ngram_set(input_list, ngram_value=2):
return set(zip(*[input_list[i:] for i in range(ngram_value)]))
# Add n-gram, augment the input list of list (sequences) by appending n-grams values
def add_ngram(sequences, token_indice, ngram_range=2):
new_sequences = []
for input_list in sequences:
new_list = input_list[:]
for ngram_value in range(2, ngram_range + 1):
for i in range(len(new_list) - ngram_value + 1):
ngram = tuple(new_list[i:i + ngram_value])
if ngram in token_indice:
new_list.append(token_indice[ngram])
new_sequences.append(new_list)
return new_sequences
# Get a fasttext model
def fasttext(config:Configuration):
# Create an input layer, dtype='int32'
input = keras.layers.Input(shape=(config.max_length,), dtype='float32', name='input_layer')
# Create output layers
output = keras.layers.Embedding(config.num_words, config.embedding_dims, input_length=config.max_length, name='embedding_layer')(input) # Maps our vocabulary indices into embedding_dims dimensions
output = keras.layers.GlobalAveragePooling1D(name='gapl')(output) # Will average the embeddings of all words in the document
output = keras.layers.Dense(config.num_classes, activation='softmax', name='output_layer')(output) # Project to dense output layer with softmax
# Create a model from input layer and output layers
model = keras.models.Model(inputs=input, outputs=output, name='fasttext')
# Compile the model
model.compile(loss='categorical_crossentropy', optimizer=keras.optimizers.adam(lr=0.01, clipnorm=0.001), metrics=['accuracy'])
# Save model summary to file
with open('C:\\DATA\\Python-data\\20news_bydate\\fasttext\\model-summary.txt', 'w') as file:
with contextlib.redirect_stdout(file):
model.summary()
# Return a model
return modelTraining
The training module is used to load the training dataset, visualize the dataset, train the model and evaluate the model on the training set. Classes, the tokenizer and the model is saved to disk after each training session (transfer learning). Output from a run is shown below the code.
# Import libraries
import os
import pickle
import keras
import keras.preprocessing
import sklearn.datasets
import numpy as np
import matplotlib.pyplot as plt
import annytab.fasttext.common as common
# Visualize dataset
def visualize_dataset(ds:object, num_classes:int):
# Print dataset
print('\n--- Information ---')
print('Number of articles: ' + str(len(ds.data)))
print('Number of categories: ' + str(len(ds.target_names)))
# Count number of articles in each category
plot_X = np.arange(num_classes, dtype=np.int16)
plot_Y = np.zeros(num_classes)
for i in range(len(ds.data)):
plot_Y[ds.target[i]] += 1
print('\n--- Class distribution ---')
for i in range(len(plot_X)):
print('{0}: {1:.0f}'.format(ds.target_names[plot_X[i]], plot_Y[i]))
# Plot the balance of the dataset
figure = plt.figure(figsize = (16, 10))
figure.suptitle('Balance of dataset', fontsize=16)
plt.bar(plot_X, plot_Y, align='center', color='rgbkymc')
plt.xticks(plot_X, ds.target_names, rotation=25, horizontalalignment='right')
#plt.show()
plt.savefig('C:\\DATA\\Python-data\\20news_bydate\\fasttext\\20-newsgroups-balance.png')
# Train and evaluate a model
def train_and_evaluate(train:object, config:common.Configuration):
# Create a dictionary with classes (maps index to name)
classes = {}
for i in range(len(train.target_names)):
classes[i] = train.target_names[i]
# Save classes to file
with open('C:\\DATA\\Python-data\\20news_bydate\\fasttext\\classes.pkl', 'wb') as file:
pickle.dump(classes, file)
print('Saved classes to disk!')
# This class allows to vectorize a text corpus, by turning each text into a sequence of integers
tokenizer = keras.preprocessing.text.Tokenizer(num_words=config.num_words)
# Updates internal vocabulary based on a list of texts
tokenizer.fit_on_texts(train.data)
# Save tokenizer to disk
with open('C:\\DATA\\Python-data\\20news_bydate\\fasttext\\tokenizer.pkl', 'wb') as file:
pickle.dump(tokenizer, file)
print('Saved tokenizer to disk!')
# Transforms each text in texts to a sequence of integers
train.data = tokenizer.texts_to_sequences(train.data)
# Converts a class vector (integers) to binary class matrix: categorical_crossentropy expects targets
# to be binary matrices (1s and 0s) of shape (samples, classes)
train.target = keras.utils.to_categorical(train.target, num_classes=config.num_classes, dtype='int32')
# Add n-gram features
if config.ngram_range > 1:
# Create set of unique n-gram from the training set
ngram_set = set()
for input_list in train.data:
for i in range(2, config.ngram_range + 1):
set_of_ngram = common.create_ngram_set(input_list, ngram_value=i)
ngram_set.update(set_of_ngram)
# Dictionary mapping n-gram token to a unique integer, integer values are greater than number of words in order to avoid collision with existing features
start_index = config.num_words + 1
token_indice = {v: k + start_index for k, v in enumerate(ngram_set)}
indice_token = {token_indice[k]: k for k in token_indice}
# Number of words is the highest integer that could be found in the dataset
config.num_words = np.max(list(indice_token.keys())) + 1
# Augmenting x_train and x_test with n-grams features
train.data = common.add_ngram(train.data, token_indice, config.ngram_range)
# Pads sequences to the same length
train.data = keras.preprocessing.sequence.pad_sequences(train.data, maxlen=config.max_length)
# Get a model
if(os.path.isfile('C:\\DATA\\Python-data\\20news_bydate\\fasttext\\model.h5') == True):
model = keras.models.load_model('C:\\DATA\\Python-data\\20news_bydate\\fasttext\\model.h5')
else:
model = common.fasttext_improved(config)
# Start training
history = model.fit(train.data, train.target, batch_size=config.batch_size, epochs=config.epochs, verbose=1)
# Save model to disk
model.save('C:\\DATA\\Python-data\\20news_bydate\\fasttext\\model.h5')
print('Training completed, saved model to disk!')
# Plot training loss
plt.figure(figsize =(12,8))
plt.plot(history.history['loss'], marker='.', label='train')
plt.title('Loss')
plt.grid(True)
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend(loc='best')
plt.savefig('C:\\DATA\\Python-data\\20news_bydate\\fasttext\\loss-plot.png')
# Plot training accuracy
plt.figure(figsize =(12,8))
plt.plot(history.history['accuracy'], marker='.', label='train')
plt.title('Accuracy')
plt.grid(True)
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend(loc='best')
plt.savefig('C:\\DATA\\Python-data\\20news_bydate\\fasttext\\accuracy-plot.png')
# The main entry point for this module
def main():
# Load text files with categories as subfolder names
# Individual samples are assumed to be files stored in a two levels folder structure
# The folder names are used as supervised signal label names. The individual file names are not important.
train = sklearn.datasets.load_files('C:\\DATA\\Python-data\\20news_bydate\\20news-bydate-train', shuffle=False, load_content=True, encoding='latin1')
# Get a configuration
config = common.Configuration()
# Visualize dataset
#visualize_dataset(train, config.num_classes)
# Preprocess data
train.data = common.preprocess_data(train.data)
# Print cleaned data
#print(train.data[0])
# Print empty row
print()
# Start training
train_and_evaluate(train, config)
# Tell python to run main method
if __name__ == "__main__": main()10784/11314 [===========================>..] - ETA: 9s - loss: 0.1440 - accuracy: 0.9651
10816/11314 [===========================>..] - ETA: 8s - loss: 0.1436 - accuracy: 0.9652
10848/11314 [===========================>..] - ETA: 7s - loss: 0.1435 - accuracy: 0.9652
10880/11314 [===========================>..] - ETA: 7s - loss: 0.1437 - accuracy: 0.9652
10912/11314 [===========================>..] - ETA: 6s - loss: 0.1438 - accuracy: 0.9652
10944/11314 [============================>.] - ETA: 6s - loss: 0.1439 - accuracy: 0.9652
10976/11314 [============================>.] - ETA: 5s - loss: 0.1443 - accuracy: 0.9650
11008/11314 [============================>.] - ETA: 5s - loss: 0.1446 - accuracy: 0.9649
11040/11314 [============================>.] - ETA: 4s - loss: 0.1442 - accuracy: 0.9650
11072/11314 [============================>.] - ETA: 4s - loss: 0.1449 - accuracy: 0.9649
11104/11314 [============================>.] - ETA: 3s - loss: 0.1445 - accuracy: 0.9650
11136/11314 [============================>.] - ETA: 3s - loss: 0.1455 - accuracy: 0.9647
11168/11314 [============================>.] - ETA: 2s - loss: 0.1451 - accuracy: 0.9648
11200/11314 [============================>.] - ETA: 1s - loss: 0.1447 - accuracy: 0.9649
11232/11314 [============================>.] - ETA: 1s - loss: 0.1444 - accuracy: 0.9650
11264/11314 [============================>.] - ETA: 0s - loss: 0.1441 - accuracy: 0.9651
11296/11314 [============================>.] - ETA: 0s - loss: 0.1447 - accuracy: 0.9650
11314/11314 [==============================] - 194s 17ms/step - loss: 0.1445 - accuracy: 0.9651
Training completed, saved model to disk!Evaluation
Model performance is evaluated on the test dataset, the model has been trained in about 140 epochs. The accuracy on the test dataset is much lower than the accuracy reported during training, this indicates that the model is underfitted (to simple). Output from an evaluation run is shown below the code.
# Import libraries
import keras
import pickle
import numpy as np
import sklearn.datasets
import sklearn.metrics
import annytab.fasttext.common as common
# Test and evaluate a model
def test_and_evaluate(ds:object, config:common.Configuration):
# Load models
model = keras.models.load_model('C:\\DATA\\Python-data\\20news_bydate\\fasttext\\model.h5')
with open('C:\\DATA\\Python-data\\20news_bydate\\fasttext\\classes.pkl', 'rb') as file:
classes = pickle.load(file)
with open('C:\\DATA\\Python-data\\20news_bydate\\fasttext\\tokenizer.pkl', 'rb') as file:
tokenizer = pickle.load(file)
# Transforms each text in texts to a sequence of integers
ds.data = tokenizer.texts_to_sequences(ds.data)
# Add n-gram features
if config.ngram_range > 1:
# Create set of unique n-gram from the dataset
ngram_set = set()
for input_list in ds.data:
for i in range(2, config.ngram_range + 1):
set_of_ngram = common.create_ngram_set(input_list, ngram_value=i)
ngram_set.update(set_of_ngram)
# Dictionary mapping n-gram token to a unique integer, integer values are greater than number of words in order to avoid collision with existing features
start_index = config.num_words + 1
token_indice = {v: k + start_index for k, v in enumerate(ngram_set)}
indice_token = {token_indice[k]: k for k in token_indice}
# Augmenting data with n-grams features
ds.data = common.add_ngram(ds.data, token_indice, config.ngram_range)
# Pads sequences to the same length
ds.data = keras.preprocessing.sequence.pad_sequences(ds.data, maxlen=config.max_length)
# Make predictions
predictions = model.predict(ds.data)
# Print results
print('\n-- Results --')
accuracy = sklearn.metrics.accuracy_score(ds.target, np.argmax(predictions, axis=1))
print('Accuracy: {0:.2f} %'.format(accuracy * 100.0))
print('Classification Report:')
print(sklearn.metrics.classification_report(ds.target, np.argmax(predictions, axis=1), target_names=list(classes.values())))
print('\n-- Samples --')
for i in range(20):
print('{0} --- Predicted: {1}, Actual: {2}'.format('CORRECT' if np.argmax(predictions[i]) == ds.target[i] else 'INCORRECT', classes.get(np.argmax(predictions[i])), classes.get(ds.target[i])))
print()
# The main entry point for this module
def main():
# Load test dataset (shuffle it to get different samples each time)
test = sklearn.datasets.load_files('C:\\DATA\\Python-data\\20news_bydate\\20news-bydate-test', shuffle=True, load_content=True, encoding='latin1')
# Preprocess data
test.data = common.preprocess_data(test.data)
# Get a configuration
config = common.Configuration()
# Test and evaluate
test_and_evaluate(test, config)
# Tell python to run main method
if __name__ == "__main__": main()-- Results --
Accuracy: 51.95 %
Classification Report:
precision recall f1-score support
alt.atheism 0.41 0.42 0.42 319
comp.graphics 0.51 0.57 0.54 389
comp.os.ms-windows.misc 0.60 0.51 0.55 394
comp.sys.ibm.pc.hardware 0.68 0.45 0.54 392
comp.sys.mac.hardware 0.62 0.56 0.59 385
comp.windows.x 0.81 0.49 0.61 395
misc.forsale 0.79 0.65 0.71 390
rec.autos 0.61 0.61 0.61 396
rec.motorcycles 0.54 0.65 0.59 398
rec.sport.baseball 0.19 0.93 0.32 397
rec.sport.hockey 0.89 0.61 0.73 399
sci.crypt 0.82 0.47 0.60 396
sci.electronics 0.60 0.35 0.44 393
sci.med 0.73 0.49 0.59 396
sci.space 0.77 0.53 0.63 394
soc.religion.christian 0.73 0.50 0.59 398
talk.politics.guns 0.49 0.46 0.47 364
talk.politics.mideast 0.89 0.43 0.58 376
talk.politics.misc 0.36 0.37 0.36 310
talk.religion.misc 0.37 0.15 0.22 251
accuracy 0.52 7532
macro avg 0.62 0.51 0.53 7532
weighted avg 0.63 0.52 0.54 7532
-- Samples --
CORRECT --- Predicted: rec.sport.hockey, Actual: rec.sport.hockey
CORRECT --- Predicted: talk.politics.guns, Actual: talk.politics.guns
INCORRECT --- Predicted: rec.sport.baseball, Actual: sci.space
CORRECT --- Predicted: talk.politics.misc, Actual: talk.politics.misc
INCORRECT --- Predicted: rec.sport.baseball, Actual: comp.windows.x
INCORRECT --- Predicted: talk.politics.misc, Actual: rec.autos
CORRECT --- Predicted: comp.os.ms-windows.misc, Actual: comp.os.ms-windows.misc
CORRECT --- Predicted: rec.autos, Actual: rec.autos
INCORRECT --- Predicted: comp.sys.mac.hardware, Actual: comp.graphics
CORRECT --- Predicted: comp.graphics, Actual: comp.graphics
CORRECT --- Predicted: comp.graphics, Actual: comp.graphics
CORRECT --- Predicted: comp.graphics, Actual: comp.graphics
INCORRECT --- Predicted: rec.sport.baseball, Actual: sci.med
CORRECT --- Predicted: soc.religion.christian, Actual: soc.religion.christian
INCORRECT --- Predicted: comp.os.ms-windows.misc, Actual: comp.sys.ibm.pc.hardware
CORRECT --- Predicted: sci.space, Actual: sci.space
INCORRECT --- Predicted: rec.sport.baseball, Actual: comp.sys.mac.hardware
CORRECT --- Predicted: rec.sport.hockey, Actual: rec.sport.hockey
CORRECT --- Predicted: soc.religion.christian, Actual: soc.religion.christian
CORRECT --- Predicted: comp.os.ms-windows.misc, Actual: comp.os.ms-windows.misc